

Last update: @5/15/2023










주의
본 포스팅은 인프런 강의를 통해 학습한 내용을 임의로 요약한 것으로 일부 내용의 오류 및 누락, 링크 숨김 등이 존재합니다.
HTTP 요청에 대해 HTML이 아닌 JSON 형태로 응답한 후 클라이언트 사이드에서 HTML을 직접 렌더링 하는 것을 보통 REST API 방식이라고 부르고, 편의상 API라고 함.
API JSON 요청
•
HTTP 요청 시 HTTP 메시지 바디에 JSON 형태로 요청 데이터를 전달함
•
이 JSON 형태의 요청 데이터는 아래처럼 @RequestBody를 통해 받을 수 있음
•
엔티티를 직접 받기보다 DTO를 이용하는 것이 좋음(사실상 필수)
@PostMapping("/api/v2/members")
public CreateMemberResponse saveMemberV2(@RequestBody @Valid CreateMemberRequest request) {
Member member = new Member();
member.setName(request.getName());
Long id = memberService.join(member);
return new CreateMemberResponse(id);
}
Java
복사
◦
@ModelAttribute처럼 @Valid로 자바 빈 검증기 사용 가능
API JSON 응답
•
클래스 레벨에 @RestController 부착
◦
@RestController는 @Controller + @ResponseBody
•
객체를 return하면 객체 → JSON 변환 라이브러리인 Jackson을 통해 JSON이 HTTP 응답으로 나감
조회
•
컬렉션을 직접 반환하는 것은 JSON Array를 직접 반환하게 되기 때문에 추후에 컬렉션 이외의 데이터를 추가할 때 유연성이 떨어짐
◦
따라서 보통 Result 클래스로 한 번 감싸서 응답함
◦
역시 DTO를 통해 응답하는 것이 좋음
@RestController
@RequiredArgsConstructor
public class MemberApiController {
private final MemberService memberService;
@GetMapping("/api/v2/members")
public Result getMembersV2() {
List<MemberDto> collect = memberService.findMembers()
.stream()
.map(m -> new MemberDto(m.getName()))
.collect(Collectors.toList());
return new Result(collect.size(), collect);
}
@Data
@AllArgsConstructor
static class Result<T> {
private int count;
private T data;
}
@Data
@AllArgsConstructor
static class MemberDto {
private String name;
}
}
Java
복사
지연로딩과 무한루프 및 프록시 (참고한 질문과 답변)
@Entity
@Table(name = "orders")
@Getter @Setter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Order {
...
@OneToOne(fetch = LAZY, cascade = CascadeType.ALL)
@JoinColumn(name = "delivery_id")
private Delivery delivery;
...
}
Java
복사
•
위처럼 지연로딩을 설정하게 되면 Order 데이터를 가져올 때 delivery 필드에 Delivery 클래스를 상속받은 프록시 객체가 들어옴
◦
이 프록시 객체에는 아래와 같은 필드들이 존재하게 됨
1.
id (기존 Delivery 필드)
2.
order (기존 Delivery 필드)
3.
address (기존 Delivery 필드)
4.
hibernateLazyInitializer (프록시 관련 필드)
◦
Jackson에서 Delivery 객체를 JSON으로 변환할 때 2번 Order 객체를 다시 객체로 변환하기 위해 order에 들어가면 다시 delivery 필드를 마주침
◦
위와 같은 원리로 무한루프에 빠져서 Memory가 터지고 에러가 남
•
무한루프를 막기 위해 Delivery 객체의 Order 필드에 @JsonIgnore를 붙여줘 Delivery의 order 필드는 Jackson이 JSON으로 만들지 않도록 처리함
@Entity
@Getter @Setter
public class Delivery {
...
@JsonIgnore
@OneToOne(mappedBy = "delivery", fetch = LAZY)
private Order order;
...
}
Java
복사
◦
이렇게 되면 무한 루프는 해결됨. 하지만 Order 객체를 JSON으로 만들 때 4. hibernateLazyInitializer 필드를 만날 때 JSON으로 변환할 수 없기 때문에 오류가 남
•
따라서 지연 로딩 설정된 것을 강제 로딩되도록 Hibernate5Module을 import 후 FORCE_LAZY_LOADING 설정을 해주고 무한 루프를 막기 위해 역참조 필드에 @JsonIgnore을 붙여주면 문제가 해결됨
◦
사실상 쓸 일이 거의 없으니 코드는 생략
(x-to-one) 엔티티 조회 vs DTO 직접 조회(프로젝션)
•
JPA에서 지연 로딩으로 설정하면 조회 한 번에 쿼리가 N + N + … 개씩 더 나가는 N+1 문제가 터짐
◦
이를 최적화 하기 위해 엔티티를 fetch join 후 DTO로 매핑하거나 DTO를 직접 프로젝션하여 사용하는 방법 두 가지가 있음
•
Entity를 통해 fetch join 후 DTO로 매핑하는 방법
@GetMapping("/api/v3/simple-orders")
public List<SimpleOrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllWithMemberDelivery();
return orders.stream()
.map(SimpleOrderDto::new)
.collect(Collectors.toList());
}
@Data
static class SimpleOrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public SimpleOrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress();
}
}
Java
복사
controller
public List<Order> findAllWithMemberDelivery() {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d", Order.class
).getResultList();
}
Java
복사
repository
◦
재사용성이 높고 fetch join으로 간단하게 성능 최적화 가능
•
DTO를 프로젝션해서 직접 조회하는 방법
public List<OrderSimpleQueryDto> findOrderDtos() {
return em.createQuery(
"select new jpabook.jpashop.repository.OrderSimpleQueryDto(" +
"o.id," +
"m.name," +
"o.orderDate," +
"o.status," +
"d.address) " +
"from Order o" +
" join o.member m" +
" join o.delivery d", OrderSimpleQueryDto.class
).getResultList();
}
Java
복사
repository
◦
필요한 데이터만 가져올 수 있고 x-to-one 연관관계를 가져올 때 최적화 가능
◦
하지만 코드가 매우 복잡해지고 재사용성이 낮음
•
두 방법 모두 여의치 않으면 Native SQL이나 JDBC Template 사용
(x-to-many) 컬렉션 엔티티 조회 vs DTO 직접 조회(프로젝션)
•
x대다(x-to-many) 관계에서 컬렉션을 가져오는 경우도 N+1 문제가 발생함
•
이를 해결하기 위해 fetch join 후 JPQL에 distinct 사용하게 된다면 모든 조회 데이터를 메모리에 올리기 때문에 매우 위험하고, 따라서 페이징이 불가능함
public List<Order> findAllWithItem() {
return em.createQuery(
"select distinct o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i", Order.class)
.getResultList();
}
Java
복사
•
위 문제를 해결하기 위해 hibernate.default_batch_fetch_size 또는 @BatchSize를 통해 배치 사이즈를 설정
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 100
YAML
복사
application.yml
◦
개별로 설정하려면 @BatchSize 를 적용하면 됨 (컬렉션은 컬렉션 필드에, 엔티티는 엔티티 클래스) - 하지만 보통 글로벌 설정으로 많이 씀
◦
보통 100~500정도 주고, 보통 DB에서 WHERE IN문의 한계가 1000이기 때문에 1000을 max로 보면 됨
◦
위 설정 후 x-to-one은 fetch join을 통해 가져오고, x-to-many 컬렉션은 로딩 지연 후 for문을 통해 지연로딩함
@GetMapping("/api/v3/orders")
public List<OrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllWithItem();
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(toList());
return result;
}
Java
복사
controller
public List<Order> findAllWithItem() {
return em.createQuery(
"select distinct o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i", Order.class)
.getResultList();
}
Java
복사
repository
◦
이렇게 하면 for문을 돌 때 매 loop마다 쿼리가 나가는 게 아니라 WHERE IN 쿼리에 넣을 ID를 BatchSize만큼 모을 때마다 쿼리를 날림(또는 for문이 종료될 때)
•
DTO로 직접 조회를 할 수 있는데, DTO는 엔티티가 아니기 때문에 BatchSize가 적용이 안 됨
◦
따라서 아래처럼 개발자가 직접 WHERE IN에 들어갈 엔티티 id값을 모아서 쿼리로 날리거나
public List<OrderQueryDto> findAllByDto_optimization() {
//루트 조회(toOne 코드를 모두 한번에 조회)
List<OrderQueryDto> result = findOrders();
List<Long> orderIds = result.stream()
.map(o -> o.getOrderId())
.collect(Collectors.toList());
//orderItem 컬렉션을 MAP 한방에 조회
List<OrderItemQueryDto> orderItems = em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(" +
" oi.order.id," +
" i.name," +
" oi.orderPrice," +
" oi.count" +
")" +
" from OrderItem oi" +
" join oi.item i" +
" where oi.order.id in :orderIds"
, OrderItemQueryDto.class).setParameter("orderIds", orderIds).getResultList();
Map<Long, List<OrderItemQueryDto>> orderItemMap = orderItems.stream()
.collect(Collectors.groupingBy(orderItemQueryDto -> orderItemQueryDto.getOrderId()));
//루프를 돌면서 컬렉션 추가(추가 쿼리 실행X)
result.forEach(o -> o.setOrderItems(orderItemMap.get(o.getOrderId())));
return result;
}
Java
복사
◦
직접 필요한 테이블을 모조리 join한 무식한 쿼리를 메모리로 퍼올려 수동 페이징을 해주는 방법이 있음
@GetMapping("/api/v6/orders")
public List<OrderQueryDto> ordersV6() {
List<OrderFlatDto> flats = orderQueryRepository.findAllByDto_flat();
return flats.stream()
.collect(groupingBy(o -> new OrderQueryDto(o.getOrderId(),
o.getName(), o.getOrderDate(), o.getOrderStatus(), o.getAddress()),
mapping(o -> new OrderItemQueryDto(o.getOrderId(),
o.getItemName(), o.getOrderPrice(), o.getCount()), toList())
)).entrySet().stream()
.map(e -> new OrderQueryDto(e.getKey().getOrderId(),
e.getKey().getName(), e.getKey().getOrderDate(), e.getKey().getOrderStatus(),
e.getKey().getAddress(), e.getValue()))
.collect(toList());
}
Java
복사
물론 메모리 문제로 페이징이 불가능하고, 쿼리는 한번만 가지만 중복 데이터를 퍼올리기 때문에 오히려 이전 방법보다 조회 성능이 느릴 수 있음
•
따라서 조회는 엔티티를 통해 하고, DTO로 매핑해주는 쪽이 일반적으로 더 좋다고 볼 수 있음
최적화 요약
•
아래 우선순위로 최적화 시도
1.
엔티티 조회 방식 사용
a.
feth join으로 쿼리 수 최적화
b.
컬렉션 최적화
i.
페이징이 필요할 경우 - BatchSize 설정으로 최적화
ii.
페이징이 필요 없을 경우 - fetch join 사용
2.
DTO 조회 방식 사용
3.
NativeSQL 또는 JdbcTemplate 사용
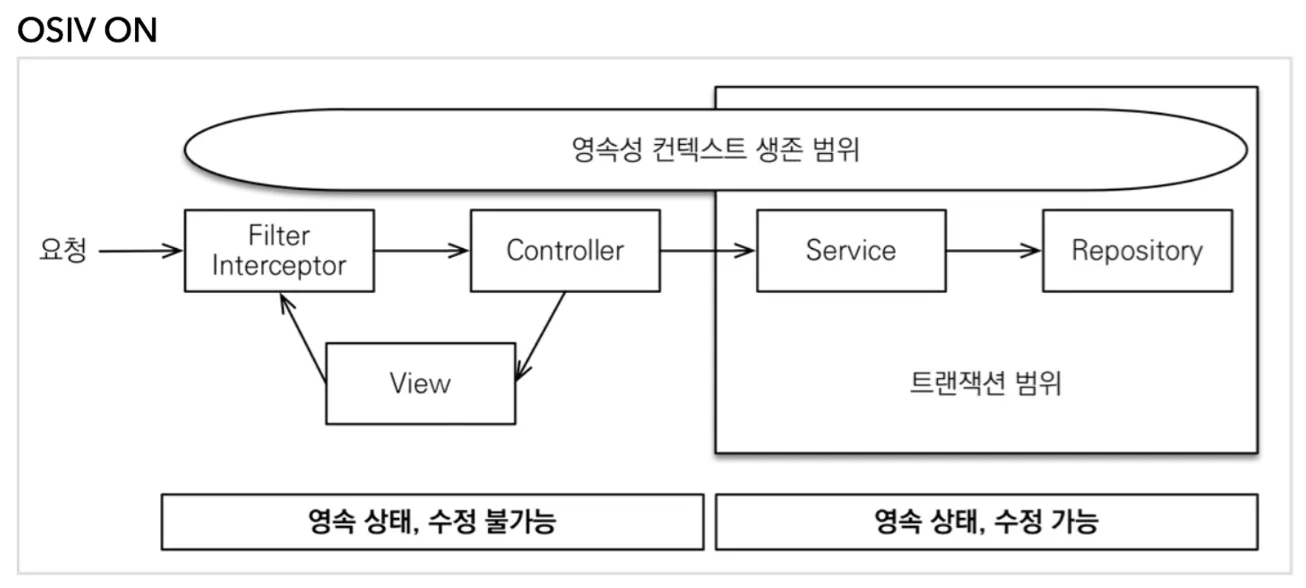
OSIV (Open Session In View)
•
영속성 컨텍스트는 @Transactional이 붙은 메서드, 즉 트랜잭션이 시작될 때 라이프사이클이 시작됨
◦
일반적으로 Service 계층에서 트랜잭션을 시작함
◦
영속성 컨텍스트가 종료되는 시점은 spring.jpa.open-in-view 설정이 true(기본값)일 때, 컨트롤러가 return될 때까지임
▪
즉, in-view까지 DB session이 살아있다고 해서 Open Session In View
▪
따라서 트랜잭션이 종료되더라도 컨트롤러단에서 Lazy Loading이 가능함
◦
만약 spring.jpa.open-in-view 설정을 false로 바꾸면 트랜잭션이 끝나면서 영속성 컨텍스트도 사라짐
▪
즉, 컨트롤러에서 호출한 서비스 계층 메서드가 종료되면 영속성 컨텍스트도 끝나버림
▪
이럴 경우 controller단에서는 엔티티의 Lazy Loading이 불가능해지는 문제가 발생함
•
만약 OSIV 옵션을 켜둔 채로 외부 API 호출처럼 응답시간이 긴 작업을 처리하면 얼마 지나지 않아 커넥션풀이 고갈되는 치명적인 문제가 생김
•
따라서 프로젝트가 모듈화 되었다는 가정 하에 고객 서비스와 같은 실시간 API는 OSIV를 끄고, ADMIN 처럼 커넥션을 많이 사용하지 않는 곳에서는 OSIV를 켜는 등의 적절한 운용이 필요함