

Last update: @2/23/2023










주의
본 포스팅은 인프런 강의를 통해 학습한 내용을 임의로 요약한 것으로 일부 내용의 오류 및 누락, 링크 숨김 등이 존재합니다.


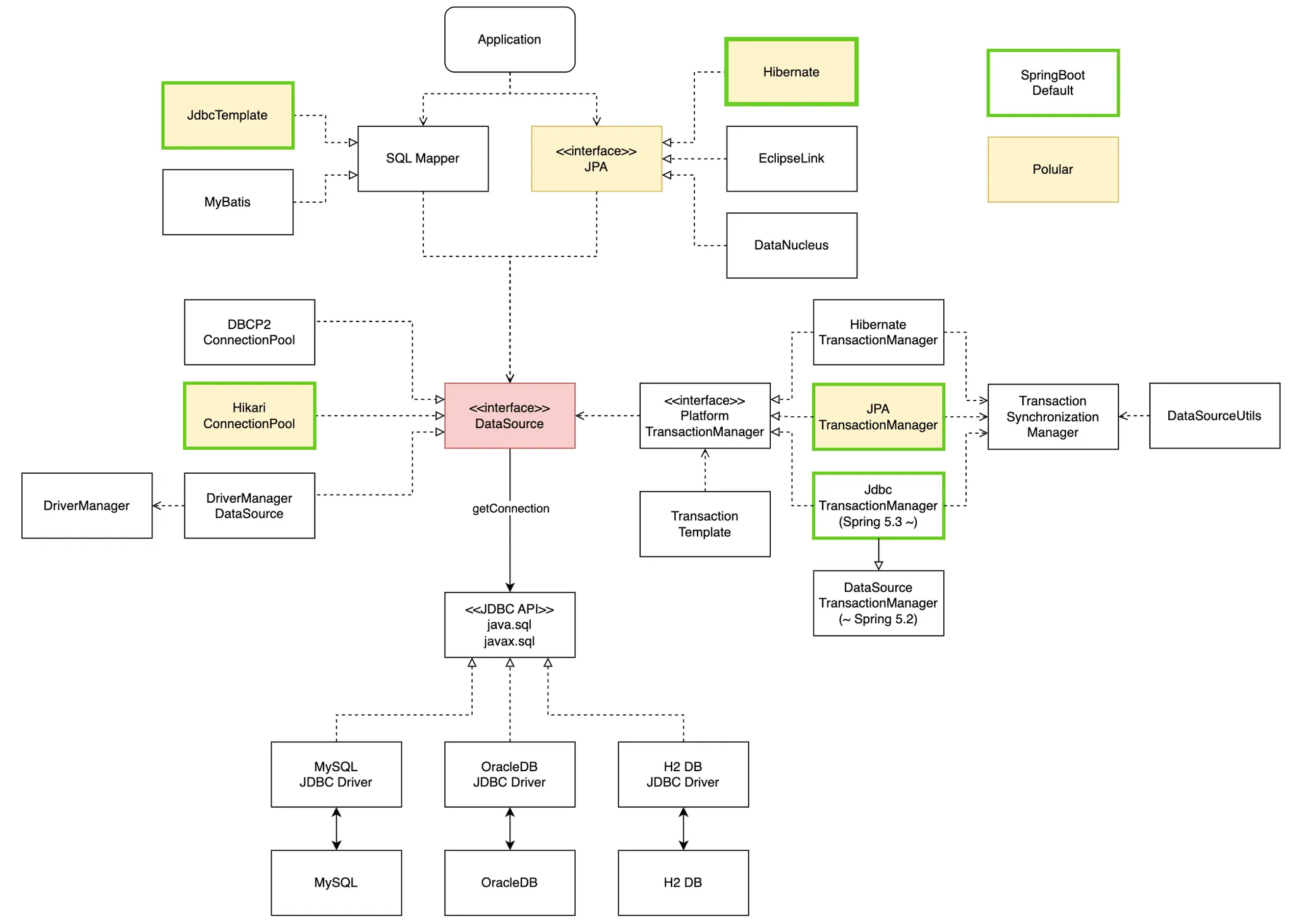
로깅 레벨 설정
#Spring Transaction
logging.level.org.springframework.transaction.interceptor=TRACE
logging.level.org.springframework.jdbc.datasource.DataSourceTransactionManager=DEBUG
#JdbcTemplate
logging.level.org.springframework.jdbc=debug
#MyBatis
logging.level.hello.itemservice.repository.mybatis=trace
#JPA log
logging.level.org.hibernate.SQL=DEBUG
logging.level.org.hibernate.type.descriptor.sql.BasicBinder=TRACE
Shell
복사
식별자 전략
•
자연 키(natural key. 주민등록번호 등)보다는 대리 키(surrogate key. 시퀀스, identity, auto_increment 등) 권장
JdbcTemplate
•
SQL을 직접 사용하는 경우에 좋음
◦
장점
▪
설정이 편리
▪
반복 문제 해결
◦
단점
▪
동적 SQL 해결이 어려움
•
설정법(build.gradle)
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
Java
복사
◦
DataSource는 스프링에 자동 등록되는 빈을 주입받으면 됨(default HikariDataSource)
•
RowMapper 필요 → 데이터베이스 조회 결과를 개체로 변환할 때 사용
•
순서 대신 이름을 지정해서 파라미터 매핑 - NamedParameterJdbcTemplate를 대신 사용
◦
SqlParameterSource
▪
BeanPropertySqlParameterSource
▪
MapSqlParameterSource
◦
BeanPropertyRowMapper
▪
스네이크 표기법을 카멜 표기법으로 자동 변환해주는 기능 내장
•
SimpleJdbcInsert로 간단한 Insert SQL 작성 없이 insert가능
•
자세한 사용법은 강의자료 참고
spring profile 설정
•
test 디렉터리 application.properties
spring.profiles.active=test
Java
복사
◦
ItemServiceApplication.class
@Bean
@Profile("local")
public TestDataInit testDataInit(ItemRepository itemRepository) {
return new TestDataInit(itemRepository);
}
Java
복사
◦
위처럼 설정하면 SpringBootTest 시 TestDataInit 클래스가 빈으로 등록되지 않음
•
테스트 DB 분리
◦
main
spring.profiles.active=local
spring.datasource.url=jdbc:h2:tcp://localhost/~/test
spring.datasource.username=sa
Java
복사
◦
test
spring.profiles.active=test
spring.datasource.url=jdbc:h2:tcp://localhost/~/testcase
spring.datasource.username=sa
Java
복사
테스트 시 @Transactional 자동 롤백
•
테스트 클래스에 @Transactional을 부착하면 테스트 중 커밋이 되지 않고 종료 후 자동 롤백 됨
•
강제로 커밋하고 싶으면 @Commit 또는 @Rollback(value = false)
임베디드 모드 DB
•
수동 설정
◦
설정파일에 다음 추가
@Bean
@Profile("test")
public DataSource dataSource() {
log.info("메모리 데이터베이스 초기화");
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("org.h2.Driver");
dataSource.setUrl("jdbc:h2:mem:db;db_CLOSE_DELAY=-1");
dataSource.setUsername("sa");
dataSource.setPassword("");
return dataSource;
}
Java
복사
▪
이후 수동으로 테이블 생성
•
스프링 부트로 자동 설정
◦
위 수동 설정에서 했던 빈 설정과, 테스트 설정 파일에서 데이터베이스 접근 정보 삭제(주석처리)
spring.profile.active=test
#spring.datasource.url=jdbc:h2:tcp://localhost/~/testcase
#spring.datasource.username=sa
Shell
복사
▪
이렇게 하면 의존성에 따라 자동으로 embedded 모드로 작동
◦
src/test/resources/schema.sql 생성해서 테이블 DDL 넣어놓으면 스프링 부트가 애플리케이션 로딩 시점에 메모리 데이터베이스를 초기화해줌
MyBatis(구 iBatis)
•
XML을 통해 편리하게 동적 쿼리 작성. 그 외는 JdbcTemplate과 거의 유사
•
설정법
◦
build.gradle
implementation 'org.mybatis.spring.boot:mybatis-spring-boot-starter:2.2.0'
Shell
복사
▪
스프링 부트가 버전을 관리해주는 공식 라이브러리가 아니라 뒤에 버전이 붙음
◦
application.properties(main 및 test 둘 다)
mybatis.type-aliases-package=hello.itemservice.domain #타입 정보 사용 시 패키지 이름 생략 가능하게 해줌
mybatis.configuration.map-underscore-to-camel-case=true #스네이크 -> 카멜 표기
Shell
복사
•
사용법
◦
마이바티스 매핑 XML을 호출해주는 매퍼 인터페이스 생성
▪
MyBatis 스프링 연동 모듈에서 proxy로 구현체를 만들어 빈으로 등록함
◦
src/main/resources에 xml 생성 - 매퍼 인터페이스가 있는 곳과 패키지 구조를 똑같이 맞춰야 함
◦
내부에 <mapper namespace=””> 태그로 매퍼 인터페이스 지정
@Autowired private final ItemMapper itemMapper;
...
itemMapper.save(item);
itemMapper.update(itemId, updateParam);
return itemMapper.findById(id);
return itemMapper.findAll(cond);
Java
복사
JPA(Java Persistence API)
•
ORM(Object-Relation Mapping) 기술의 표준 정한 인터페이스 모음
◦
Hibernate, EclipseLink, DataNucleus 세 가지 구현체 존재
•
스프링 + JPA 조합이 글로벌 점유율 80%
•
기존 문제점과 JPA
◦
자바 객체와 RDB의 개념과 활용법이 다름(패러다임 불일치)
▪
객체는 상속이 있지만 테이블은 없음
→ 저장 시 JPA에서 INSERT문을 별도로 생성해서 해결, 조회 시 JPA가 JOIN문 생성해서 조회
▪
객체는 참조를 사용, 테이블은 외래키를 사용(연관관계 불일치)
→ 객체 참조를 활용해 JPA가 연관관계를 DB에 알맞게 바꿔서 저장
▪
객체는 참조하는 다른 객체를 자유롭게 탐색 가능, 테이블은 처음 실행하는 SQL에 따라 탐색 범위 제한 → 엔티티에 데이터가 있는 지 알 수 없음
→ 객체 참조를 탐색할 때마다 JPA가 알맞은 데이터 조회해서 반환(LazyLoading)
▪
컬렉션에서 조회한 같은 객체간 == 비교와 SQL로 조회한 같은 객체의 == 비교 결과가 다름
→ JPA가 동일한 트랜잭션에서 find를 통해 조회한 두 엔티티가 같음을 보장
•
JPA는 객체를 마치 자바 컬렉션에 저장하고 사용하듯이 DB에 저장하고 사용할 수 있게 해주는 기술
•
JPA의 성능 최적화 기능
◦
1차 캐시와 동일성 보장
▪
같은 트랜잭션 안에서는 같은 엔티티 반환 - 약간의 조회 성능 향상
▪
애플리케이션에서 Repeatable Read 격리수준 보장
◦
트랜잭션을 지원하는 쓰기 지연
▪
트랜잭션 커밋까지 INSERT SQL 누적 후 JDBC BATCH SQL 기능을 통해 한번에 SQL 전송
▪
UPDATE, DELETE로 인한 row 락 최소화 //TODO_STUDY
◦
지연 로딩(Lazy Loading)
▪
객체가 실제 사용될 때 로딩
•
동적 쿼리는 해결하지 못해 QueryDSL을 이용함
JPA 설정
•
build.gradle
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
Java
복사
◦
추가되는 주요 라이브러리
▪
hibernate-core
▪
jakarta,persistence-api
▪
spring-data-jpa
JPA 사용
•
ORM 매핑
@Data
@Entity // JPA가 사용하는 객체라는 의미 - 이 객체를 엔티티라 부름
//@Table(name = "item") // 객체 명과 테이블 이름이 같으면 생략 가능
public class Item {
@Id //PK값 매핑
@GeneratedValue(strategy = GenerationType.IDENTITY) //PK값 생성 전략 - DB identity
private Long id;
@Column(name = "item_name", length = 10) // 컬럼명과 매핑
private String itemName;
public Item() {} // proxy 기술을 위해 필요
public Item(String itemName) {this.itemName = itemName;}
}
Java
복사
◦
@Column의 name 속성은 스프링 부트 사용 시 생략 가능(언더스코어  카멜 자동 변환)
카멜 자동 변환)
카멜 자동 변환)•
사용
@Autowired Entity Manager em;
...
em.persist(item); //저장
Item foundItem = em.find(Item.class, itemId); //조회
item.set... //수정 -> 자동 update
String jpql = "select i from Item i"; // 복잡한 쿼리 조회
TypedQuery<Item> query = em.createQuery(jpql, Item.class);
List<Item> result = query.getResultList();
Java
복사
•
기본 설정은 JpaBaseConfiguration 참고
JPA 예외처리
•
EntityManager는 스프링과 무관한 순수 JPA 기술이기 때문에 JPA 관련 예외(PersistenceException과 그 하위 예외)를 발생시킴
•
@Repository가 붙은 클래스는 컴포넌트 스캔 대상이 되고 예외 변환 AOP의 적용 대상이 됨
◦
스프링과 JPA를 함께 사용하면 스프링은 JPA 예외 변환기 PersistenceExceptionTranslator를 등록하고, 예외 변환 AOP에 적용하여 JPA 예외를 스프링 데이터 접근 예외로 변환함
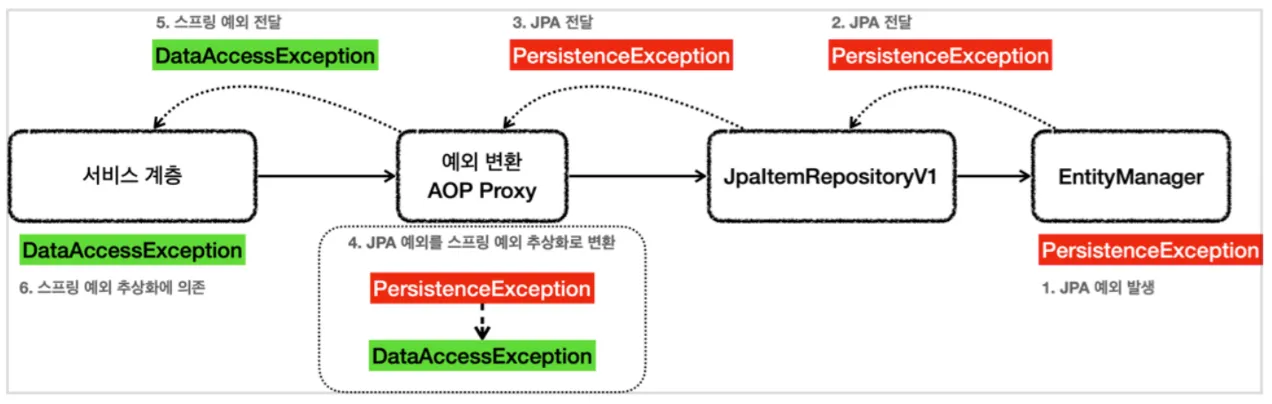
스프링 데이터 JPA
•
시장에 RDBS가 생겨나고 JPA 이외에 각 DB에 접근하는 여러 방식들이 모두 달랐음
•
이를 추상화해서 인터페이스로 만든 것이 Spring Data이고, Spring Data JPA는 그 중에 하나
•
기능
◦
CRUD + 쿼리
◦
동일한 인터페이스
◦
페이징 처리
◦
메서드 이름으로 쿼리 생성
◦
스프링 MVC에서 id 값만 넘겨도 도메인 클래스로 바인딩 등등
•
설정법(build.gradle)
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
Java
복사
•
사용법 - 사용할 Repository를 JpaRepository 인터페이스를 상속한 인터페이스로 구현
public interface MemberRepository extends JpaRepository<Member, Long> {
//JpaRepository의 기본 기능 이외에 추가로 구현하고 싶은 쿼리를 메서드 이름을 통해 작성
//인터페이스에 @Query("...")를 통해 직접 쿼리 작성 가능
}
Java
복사
◦
쿼리 메서드 기능
▪
인터페이스에 메서드만 규칙에 따라 적어두면 Spring Data JPA가 메서드 이름을 분석해서 JPQL 쿼리를 자동으로 만들고 실행해줌
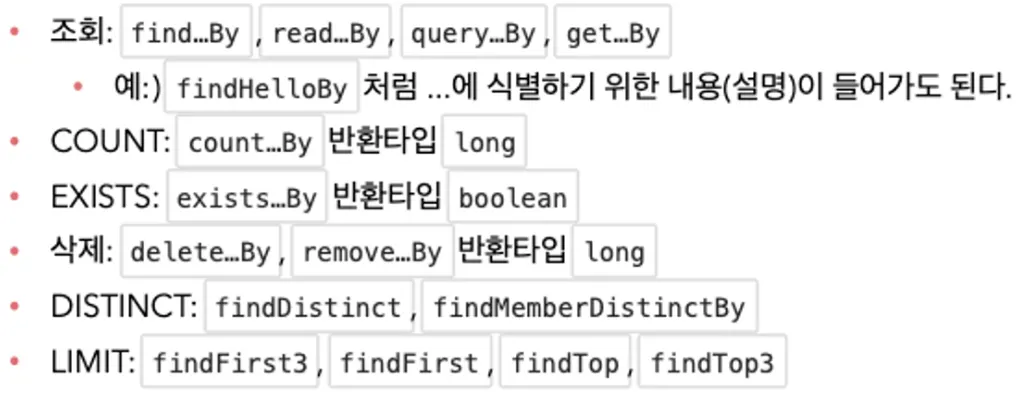
쿼리 메서드 규칙
▪
JPQL은 JPA가 다시 SQL로 변역해서 실행함
▪
메서드 이름이 너무 길어져서 읽기 힘들면 아래처럼 직접 작성
public interface SpringDataJpaItemRepository extends JpaRepository<Item, Long>{
@Query("select i from Item i where i.itemName like :itemName and i.price <= :price")
List<Item> findItems(@Param("itemName") String itemName, @Param("price") Integer price);
}
Java
복사
◦
JpaRepository 인터페이스
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
<S extends T> S save(S entity);
void delete(ID id)
Optional<T> findById(ID id)
Iterable<T> findAll();
long count()
//기타 등등 온갖 기본 및 부가 기능
}
Java
복사
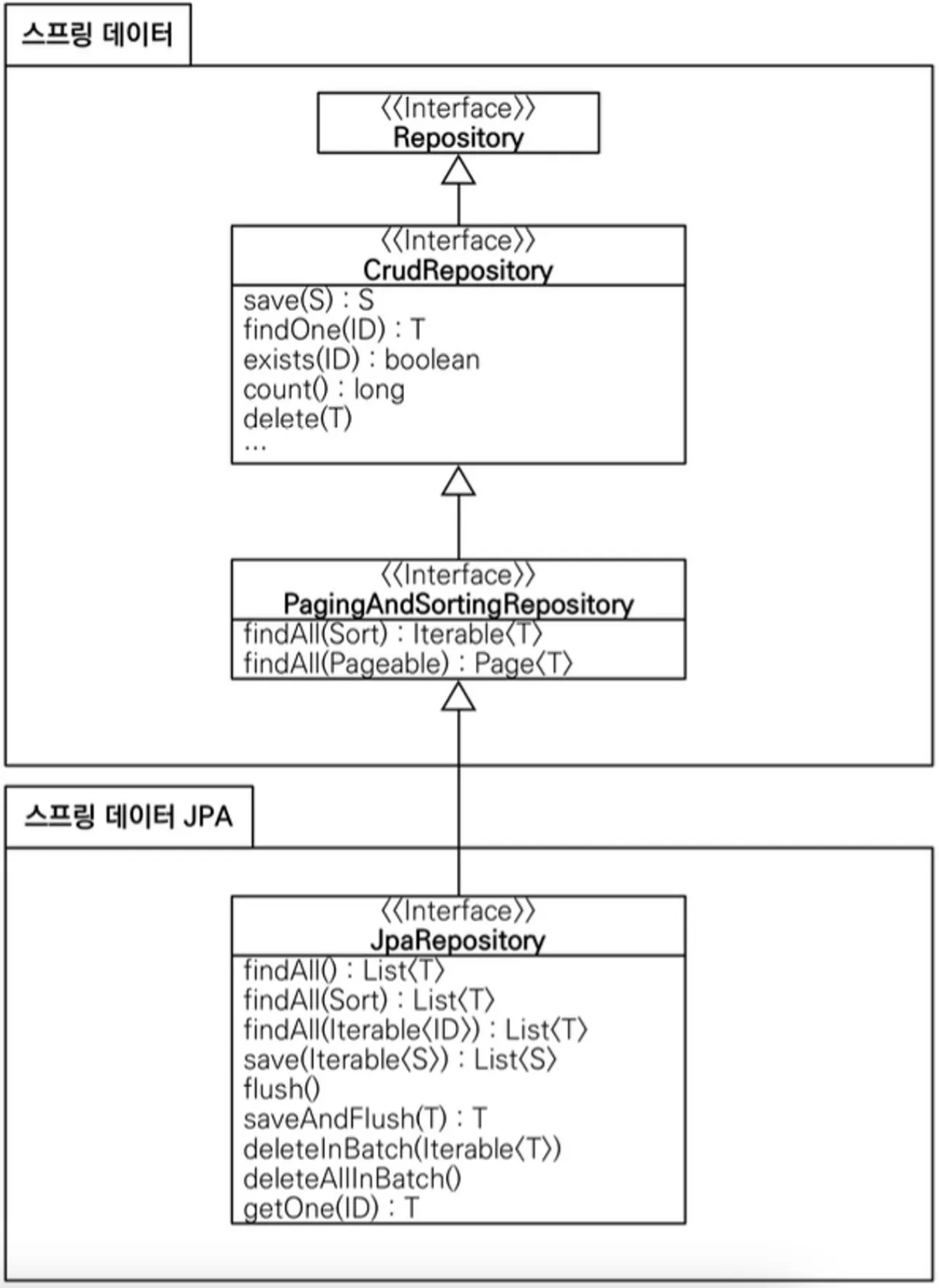
▪
JpaRepository는 org.springframework.data.repository 인터페이스를 상속해 확장한 구조
◦
이렇게 만든 Repository를 클라이언트(Service 계층)에서 의존성 주입 받아 사용하면 됨(proxy 구현체가 주입됨)
▪
Spring Data JPA가 Repository를 상속한 인터페이스를 가지고 proxy로 구현 클래스를 만들어 줌
▪
스프링 데이터 JPA도 스프링 예외 추상화를 지원하기 때문에 이 프록시에서도 내부에서 스프링 예외처리를 지원함
•
주의사항
JPA 자체를 잘 알아야 함
QueryDSL(Query Domain Specific Language)
•
JPA에서의 쿼리 방식
◦
JPQL(HQL)
: SQL과 비슷해서 익히기 쉽지만 type-safe가 아니고 동적쿼리 생성이 어려움
◦
Creteria API
: 너무 복잡함
◦
MetaModel Creteria API(type-safe)
: 너무 복잡함
•
Query의 문제
◦
문자열이라 Type-check불가능
◦
실행 전까지 작동여부 확인 불가
•
QueryDSL
◦
쿼리를 type-safe하게 개발할 수 있게 지원하는 프레임워크
▪
컴파일시 에러 체크 가능
▪
IDE의 Code-assistant 기능 활용 가능
◦
JPA, MongoBD, SQL 같은 기술들을 위해 type-safe SQL을 만듦
▪
주로 JPA 쿼리(JPQL)에 사용
•
코드 생성기를 통해 @Entity 어노테이션이 붙어있는 엔터티에 Q가 앞에 붙은 이름을 가진 Query Type 클래스를 자동 생성함(Item →QItem)
•
설정법(build.gradle)
implementation 'com.querydsl:querydsl-jpa'
annotationProcessor "com.querydsl:querydsl-apt:${dependencyManagement.importedProperties['querydsl.version']}:jpa"
annotationProcessor "jakarta.annotation:jakarta.annotation-api"
annotationProcessor "jakarta.persistence:jakarta.persistence-api"
//Querydsl 추가, 자동 생성된 Q클래스 gradle clean으로 제거
clean {
delete file('src/main/generated')
}
Java
복사
◦
Q타입 객체는 빌드 시 다음과 같은 경로로 생성됨
build -> generated -> sources -> annotationProcessor -> java/main
-> hello.itemservice.domain.QItem
Java
복사
▪
자세한 것은 참조
•
사용법
JPAQueryFactory query = new JPAQueryFactory(em);
QMember = QMember.member;
List<Member> list = query
.select(m) // SELECT id, age, name
.from(m) // FROM member
.where( // WHERE age BETWEEN 20 and 40
m.age.between(20, 40).and(m.name.like("김%"))
)
.orderBy(m.age.desc()) // ORDER BY age DESC
.limit(3) // LIMIT 3
.fetch();
Java
복사
◦
JPAQueryFactory는 JPQL을 만들기 때문에 EntityManager가 필요함
•
JPQL로 해결하기 어려운 복잡한 쿼리는 네이티브 SQL 쿼리 사용(JdbcTemplate, MyBatis)
실용적인 구조
•
기본 CRUD와 단순 조회 - Spring Data JPA 담당
•
복잡한 쿼리 - QueryDSL 담당
•
Service 계층은 위의 두 Repository를 주입받아 각각 사용
public interface ItemRepository extends JpaRepository<Item, Long> {}
Java
복사
pulbic class ItemQueryRepository {
private final JPAQueryFactory query;
//QueryDSL 사용 코드...
}
Java
복사
•
JPA + Spring Data JPA + QueryDSL을 기본으로 사용하고 복잡한 쿼리는 JdbcTemplate이나 MyBatis를 함께 사용하는 구조를 추천
◦
JPA와 JdbcTemplate을 하나의 트랜잭션에서 사용할 경우 JdbcTemplate은 JPA가 플러시하기 전에 변경한 데이터를 읽지 못하는 것에 주의
◦
또한 이렇게 하면 리포지토리 구현 기술이 변경되면 많은 코드 변경이 필요한 단점이 생김. 상황에 맞게 적절한 선택 필요
스프링 트랜잭션
•
@Transactional 어노테이션이 있는 클래스는 스프링이 AOP로 프록시를 만들어 트랜잭션 처리를 해줌
•
우선순위
◦
메서드 > 클래스 > 인터페이스 (구체적인 것이 우선)
◦
인터페이스에는 가급적 사용하지 말 것이 권장됨
스프링 트랜잭션 AOP 주의 사항
•
프록시 내부 호출 문제
◦
AOP가 적용되면 프록시가 빈으로 등록되고, 해당 빈을 주입받아 메서드를 호출하면 프록시의 메서드가 호출이 됨
◦
하지만 대상 객체의 내부에서 메서드 호출이 발생하면 프록시를 거치지 않고 대상 객체를 직접 호출하고, @Transactional이 있는 메서드라도 트랜잭션이 적용되지 않음
◦
해결 방법
▪
내부 호출을 피하기 위해 호출되는 메서드는 별로 클래스로 분리 → 실무에서 주로 사용하는 방식
▪
스프링 핵심원리 고급편에서 더 다양한 해결방안 소개
•
@PostConstruct에서 트랜잭션 미적용
◦
초기화 코드가 먼저 호출되고 그 다음 트랜잭션 AOP가 적용되기 때문
◦
해결 방법
@EventListener(ApplicationReadyEvent.class) 사용
@EventListener(ApplicationReadyEvent.class)
@Transactional
public void init() {...}
Java
복사
스프링 트랜잭션 옵션
•
vlaue, transactionManager(”빈이름”)
◦
트랜잭션 매니저 수동 설정
•
noRollbackFor/rollbackFor(예외 클래스)
◦
특정 클래스에 대해 롤백을 할 지 말 지 설정
•
propagation
◦
전파 옵션
•
isolation
◦
트랜잭션 격리 수준 설정(기본은 DB값 사용 DEFAULT)
•
timeout
◦
트랜잭션 수행시간에 대한 타임아웃을 초 단위로 지정
•
label
◦
트랜잭션 애노테이션 값 직접 읽어서 어떤 동작을 하고싶을 때 사용(잘 안 씀)
•
readOnly
◦
읽기 전용 트랜잭션으로 변경 - 등록, 수정, 삭제 불가
◦
읽기 전용 트랜잭션인 경우 적용 방식
▪
프레임워크
•
JdbcTemplate은 변경 기능을 실행하면 예외 던짐
•
JPA(Hibernate)는 커밋 시점에 플러시를 호출하지 않고, 변경 감지를 위한 스냅샷 객체도 생성하지 않음(최적화)
▪
JDBC 드라이버(드라이버와 그 버전에 따라 다르게 동작하니 참고만)
•
변경 쿼리가 들어오면 예외 발생
•
쓰기, 읽기(마스터, 슬레이브) 데이터베이스를 구분해서 요청. 읽기(슬레이브) 데이터베이스의 커넥션을 획득해서 사용
▪
데이터베이스
•
내부에서 성능 최적화가 발생
◦
ReadOnly는 보통 JPA인 경우 성능 최적화 이점을 보지만 Jdbc는 오히려 DB와 readonly 관련 통신을 하느라 성능이 저하될 수 있음(성능 테스트 필요)
스프링 트랜잭션 예외
•
기본 설정값
◦
런타임(언체크) 예외 - 롤백
▪
스프링이 일반적으로 복구가 불가능한 예외라고 가정하기 때문에 롤백
◦
체크드 예외 - 커밋
▪
스프링이 체크드 예외는 비즈니스적으로 의미가 있고 복구 가능하다고 가정하기 때문에 커밋
◦
기본 설정값을 활용해서 롤백/커밋 여부 결정 가능
◦
rollbackFor 옵션으로 예외별 롤백 지정 가능
트랜잭션 전파
•
트랜잭션 안에서 트랜잭션이 호출될 경우
◦
default 전파 옵션인 RROPAGATION_REQUIRED의 경우
▪
내부 트랜잭션은 외부 트랜잭션(global transaction)에 참여
▪
외부 또는 내부 트랜잭션 중 하나라도 롤백이 되면 둘 다 롤백
•
내부 트랜잭션이 롤백되는 경우 외부 트랜잭션에 rollback-only를 마킹함
◦
외부 트랜잭션은 rollback-only가 마킹됐기 때문에 본인은 성공하더라도 롤백됨
◦
외부 트랜잭션에 해당 사실을 알리기 위해 스프링이 UnexpectedRollbackException 예외 투척
◦
내부 트랜잭션에 런타임 예외가 터져서 자동 롤백된 경우 외부도 rollback_only 표시와 관계 없이 자동 롤백
▪
이 경우 외부 트랜잭션에서 런타임 에러를 예외처리를 하더라도 커밋할 수 없음. 커밋을 하고싶으면 내부 트랜잭션에 다음 옵션 표시
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void save(Log logMessage)
Java
복사
◦
전파옵션 RROPAGATION_REQUIRE_NEW의 경우
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void save(Log logMessage)
Java
복사
위처럼 호출되는 트랜잭션에 옵션을 걸거나 아래처럼 클라이언트에서 직접 설정
DefaultTransactionAttribute definition = new DefaultTransactionAttribute();
definition.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
TransactionStatus inner = txManager.getTransaction(definition);
Java
복사
▪
각각의 트랜잭션이 별도의 커넥션을 사용하고, 각자 성공 시 커밋, 실패 시 롤백함
•
이 외의 다양한 전파 옵션이 있지만 REQUIRES_NEW만 아주 가끔 사용하고 나머지는 거의 사용하지 않음