

Last update: @3/5/2023










주의
본 포스팅은 인프런 강의를 통해 학습한 내용을 임의로 요약한 것으로 일부 내용의 오류 및 누락, 링크 숨김 등이 존재합니다.


JPA(Java Persistence API)
•
객체와 관계형DB를 연결하는 자바의 표준 ORM(Object-Relational Mapping) 기술
◦
하이버네이트가 JPA의 대표적인 구현체
•
JPA 기술은 자바의 객체를 데이터베이스에 저장하는 것처럼 동작하도록 도와줌
•
장점
◦
단순 CRUD 시 SQL을 직접 작성할 필요가 없어짐
◦
SQL을 직접 작성할 일이 줄어들어 유지보수가 쉬워짐
◦
객체와 관계형DB의 동작 방식의 차이를 중간에서 해결해줌
▪
객체 상속관계 - DB D.type 등
▪
객체 의존관계 - DB FK 연관관계
▪
성능을 유지하면서 객체 간 탐색을 자유롭게 해주는 지연로딩
▪
같은 id로 여러번 조회한 객체는 모두 동일함을 보장(== 비교 가능)
◦
1차 캐시와 쓰기지연을 통한 약간의 성능 향상
◦
트랜잭션 격리 수준을 애플리케이션 레벨에서 REPEATABLE READ 보장
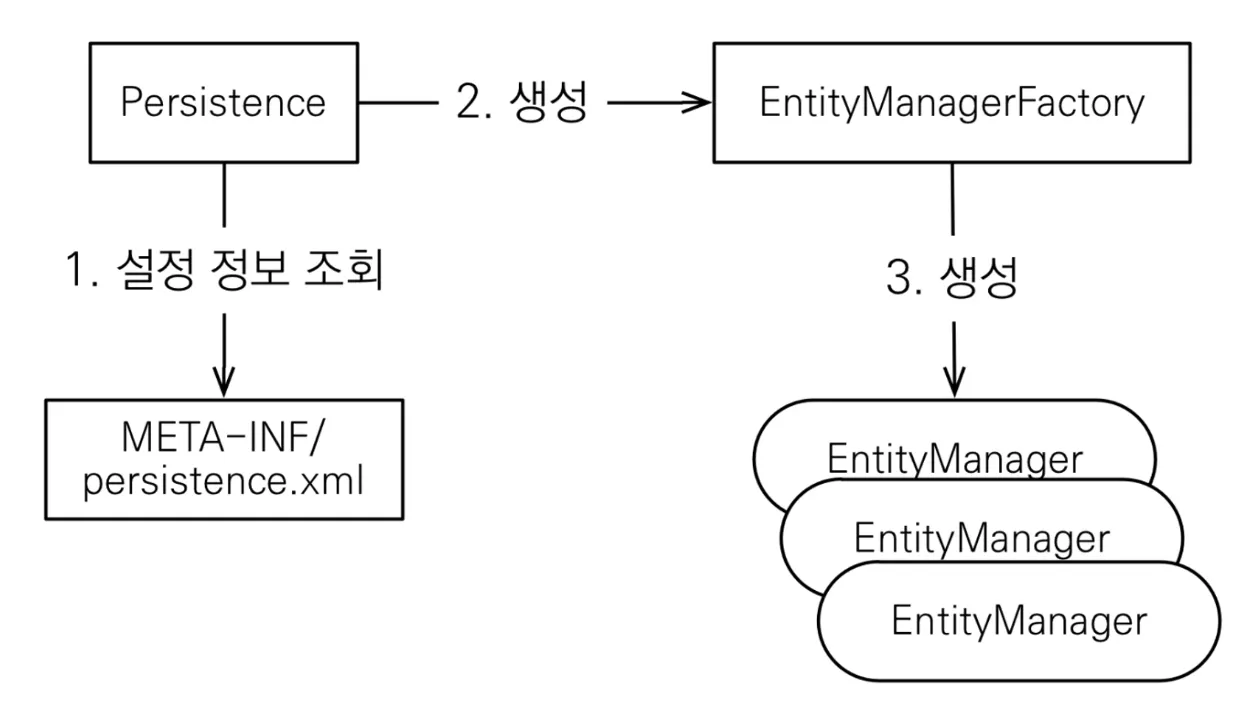
JPA 설정(Maven)
/META-INF/ 경로에 persristence.xml 파일 생성
Maven pom.xml 설정
•
DB Dialect - 추상화된 JPA 기능을 DB마다 다른 문법으로 지원해주는 API
•
JPA 기본 구동 방식
엔티티와 테이블 매핑
•
엔티티와 테이블 매핑
package hellojpa;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "USER") // @Table 어노테이션으로 직접 테이블 이름 지정 가능(옵션, 비추천)
public class Member { // final/inner 클래스, enum, interface 클래스 사용 불가
@Id // PK 매핑
private Long id; // 저장할 필드에 final 사용 불가
@Column(name = "USER_NAME") // 컬럼명 지정 가능(옵션)
private String name;
public Member() {} // 기본 생성자 필수
...
}
Java
복사
◦
테이블과 1:1 매핑되는 객체를 엔티티라고 함. @Entity 어노테이션으로 지정, 테이블은 자동 지정
◦
기본적으로 JPA 내부에서 사용하는 엔티티 이름은 클래스 이름과 같고, 테이블 이름도 클래스 이름으로 자동 매핑됨(엔티티 이름도 바꿀 수 있지만 헷갈리니 비추천)
◦
Orders의 경우는 DB 예약어라 Order 엔티티 테이블 이름을 Orders로 변경해야함
필드와 컬럼 매핑
•
필드와 컬럼 매핑
어노테이션 | 설명 |
@Column | 컬럼 매핑 |
@Temporal | 날짜 타입 매핑(자바 1.8부터 나온 LocalDateTime을 쓰면 생략 가능) |
@Enumerated | enum 타입 매핑(value 속성 Enum.Type.STRING 필수 사용) |
@Lob | BLOB, CLOB 매핑 |
@Transient | 특정 필드를 컬럼에 매핑하지 않음(매핑 무시) |
기본키 테이블 매핑
•
@Id
•
PK 자동 생성 시 @GeneratedVlaue(strategy = GenerationType.XXX)
◦
AUTO - 방언에 따라 자동 지정, 기본값
◦
IDENTITY - DB에 위임
▪
em.persist() 시점에 즉시 INSERT 쿼리 실행하여 DB에서 식별자를 조회(이 때 SQL 버퍼 내 쿼리문들이 함께 실행됨)
▪
MySQL, PostgreSQL, SQL Server, DB2 등
◦
SEQUENCE - DB 시퀀스 오브젝트 사용(ORACLE),@SequenceGenerator 필요
▪
Oracle, PostgreSQL, DB2, H2 등
▪
allocationSize로 한 번에 얻어오는 시퀀스 개수 설정 가능 - 성능 최적화
사용예
◦
TABLE - 키 생성용 테이블 사용, @TableGenerator 필요
▪
시퀀스 흉내내서 모든 DB에서 사용 가능
▪
락이 걸릴 수 있는 등 성능이 단점
사용예
EntityManager 사용법
•
스프링 없이 직접 사용하기
public class JpaMain {
public static void main(String[] args) {
// persistence.xml의 persistence-unit에 등록한 이름 입력
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
// JPA의 모든 데이터 변경은 트랜잭션 안에서 실행됨
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
Member member = new Member();
member.setId(2L);
member.setName("helloB");
em.persist(member);
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}
}
Java
복사
◦
EntityManagerFactoty는 하나만 생성해서 애플리케이션 전체에서 공유해서 사용
◦
엔티티 매니저는 쓰레드간에 공유하면 안 됨
•
EntityManager 기본 메서드
◦
삽입
Member member = new Member();
em.persist(member);
Java
복사
◦
조회
Member foundMember = em.find(Member.class, 1L);
Java
복사
◦
삭제
em.remove(foundMember);
Java
복사
◦
수정
foundMember.setName("helloJPA");
Java
복사
▪
엔티티가 영속성 컨텍스트에 들어온 순간의 상태가 스냅샷으로 저장되어, 이후 변경이 발생하면 JPA가 이를 감지해서 자동으로 update 쿼리를 보냄(Dirty Checking)
◦
플러시(SQL 전송)
em.flush();
Java
복사
▪
SQL 버퍼에 있는 SQL을 DB로 보냄. 그렇다고 커밋이 되는것은 아님
▪
트랜잭션 커밋 및 JPQL 쿼리 실행 시 플러시는 자동 호출됨
◦
영속성 컨텍스트 초기화
em.clear();
Java
복사
◦
준영속 상태로 전환
em.detach(entity);
Java
복사
◦
영속성 컨텍스트 종료
em.close();
Java
복사
EntityManager와 영속성 컨텍스트
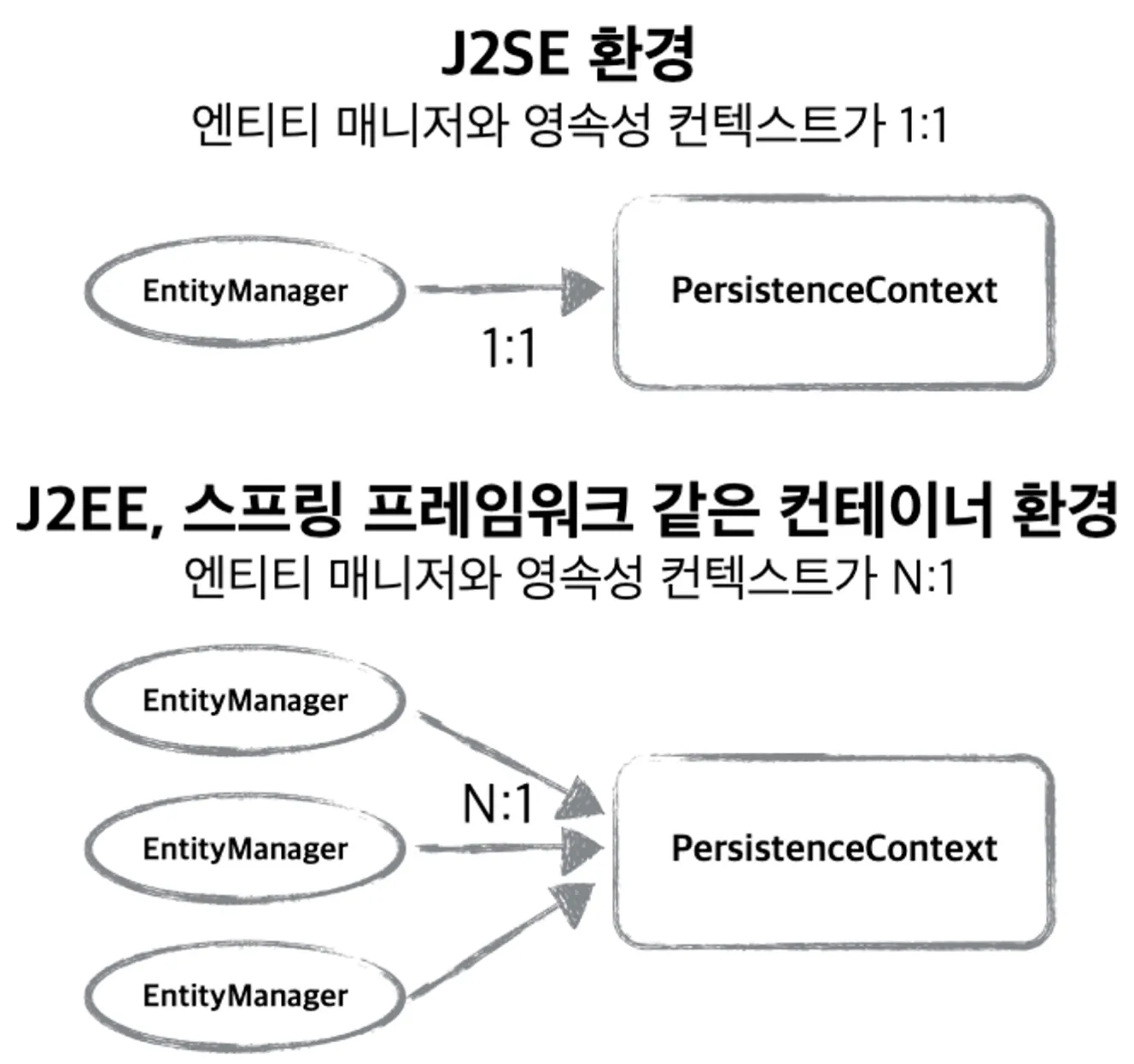
•
영속성 컨텍스트: 엔티티를 영구 저장하는 환경을 뜻하는 논리적인 개념. EntityManager를 통해 접근
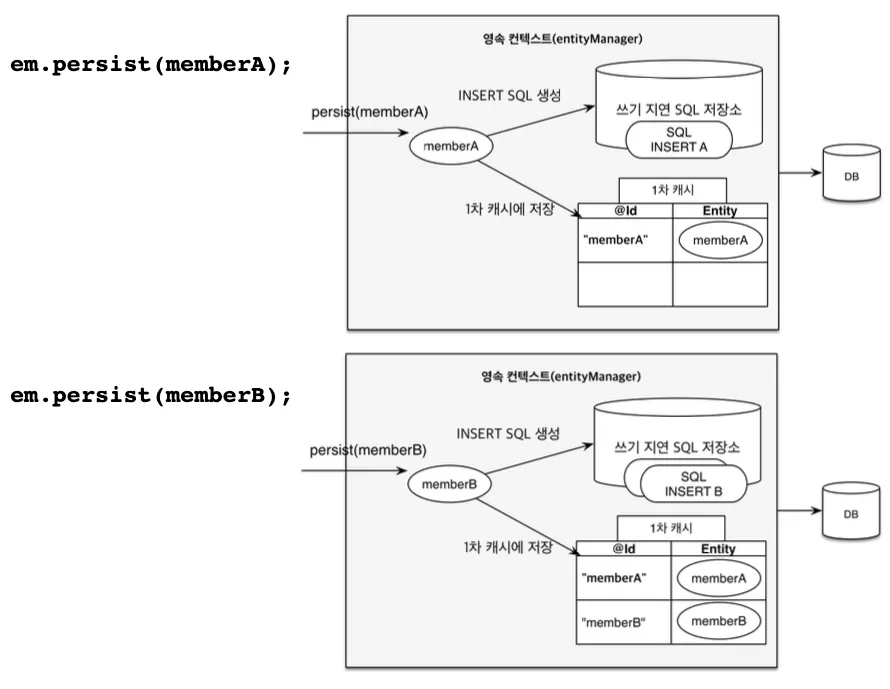
◦
id를 key로 객체를 저장하는 1차 캐시를 가지고 있음
◦
쓰기 지연을 위한 SQL 저장소가 있어 flush 또는 commit 이전에 DB에 보낼 SQL이 저장됨
•
엔티티의 생명주기
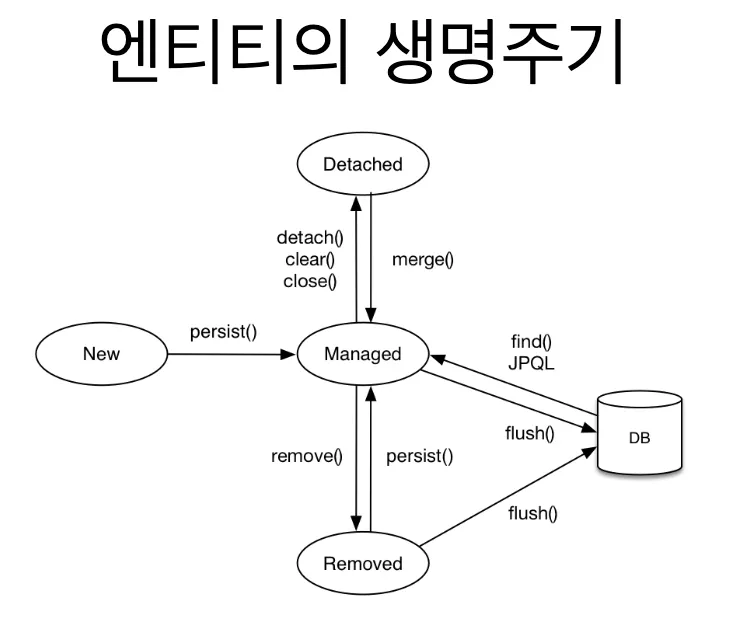
◦
비영속(new/transient)
: 영속성 컨텍스트와 전혀 관계가 없는 새로운 상태
◦
영속(managed)
: 영속성 컨텍스트에 관리되는 상태
◦
준영속(detached)
: 영속성 컨텍스트에 저장되었다가 분리된 상태
◦
삭제(removed)
: 삭제된 상태
DB 스키마 자동 생성
•
DDL을 애플리케이션 실행 시점에 자동 생성해주는 기능
◦
Maven - persistence.xml
<property name="hibernate.hbm2ddl.auto" value="create" />
Java
복사
옵션 | 설명 |
create | 기존 테이블 삭제 후 다시 생성(DROP + CREATE) |
create-drop | create와 같으나 종료시점에 테이블 DROP |
update | 변경분만 반영 |
validate | 엔티티와 테이블이 정상 매핑되었는지만 검증 |
none | 사용하지 않음(none은 관례상 쓰는거고 실제 존재하는 옵션은 아님) |
•
가급적 개발 장비에서만 사용
연관관계 매핑
•
DB는 한 테이블의 다른 테이블의 FK를 들고 있음으로써 연관관계가 맺어짐
•
객체는 한 객체가 다른 객체를 필드에 참조로 들고 있음으로써 연관관계가 맺어짐
•
양쪽 중 어느 쪽에서 FK를 관리하는지를 기준으로 다대일(N:1), 일대다(1:N), 일대일(1:1), 다대다(M:N)로 나뉨
•
다대일(N:1)(@ManyToOne)
◦
단방향(필수) - DB는 원래 다수쪽 테이블이 무조건 FK를 들고있기 때문에 컬럼을 반드시 지정
@ManyToOne(fetch = FetchType.LAZY) //Default EAGER(즉시로딩), LAZY 강력 권장
@JoinColumn(name = "TEAM_ID") // 테이블에서 FK를 들고 있는 본인의 컬럼 지정
private Team team;
Java
복사
▪
Team을 바꾸면 본인의 TEAM_ID(FK)가 수정됨
◦
양방향(옵션) - FK를 들고 있지 않은 테이블의 엔티티에서 반대 방향을 참조하고 싶을 때
@OneToMany(mappedBy = "team") // 상대 엔티티 변수명을 지정
private List<Member> members = new ArrayList<>();
Java
복사
▪
List를 수정해도 Member쪽 TEAM_ID(FK)가 변경되지 않음. 단순 읽기전용 매핑
▪
컬렉션은 필드에서 초기화해야함. 하이버네이트는 엔티티를 영속화할 때 컬렉션을 감싸서 하이버네이트가 제공하는 내장 컬렉션으로 변경함. 만약 getMembers()처럼 임의의 메서드에서 컬렉션을 잘못 생성하면 하이버네이트 내부 메커니즘에 문제가 발생할 수 있기 때문에 필드레벨에서 생성하는 것이 가장 안전하고 코드도 간결함
•
일대다(1:N)(@OneToMany)
◦
단방향(필수) - 단수쪽 테이블이 다수쪽 테이블의 FK를 관리하는 매핑. 가끔 필요함
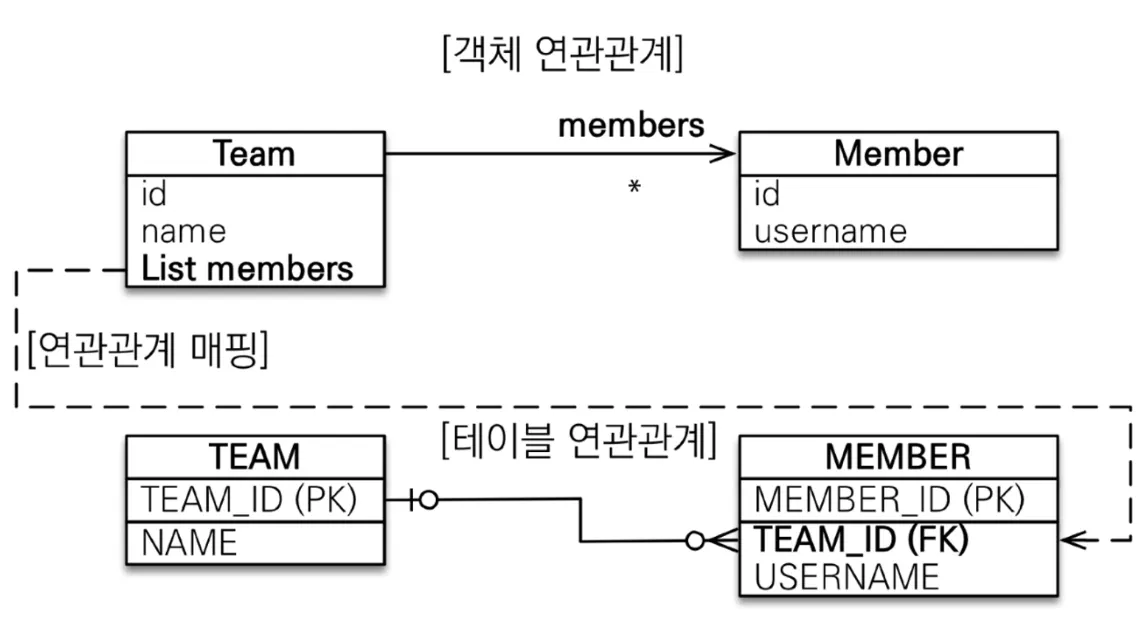
@OneToMany
@JoinColumn(name = "TEAM_ID") // 상대 엔티티 컬럼명을 지정
private List<Member> members = new ArrayList<>();
Java
복사
◦
양방향(옵션) - 공식적으로 지원은 안 하지만 단방향을 읽기전용으로 만들어 억지로 할 수는 있음
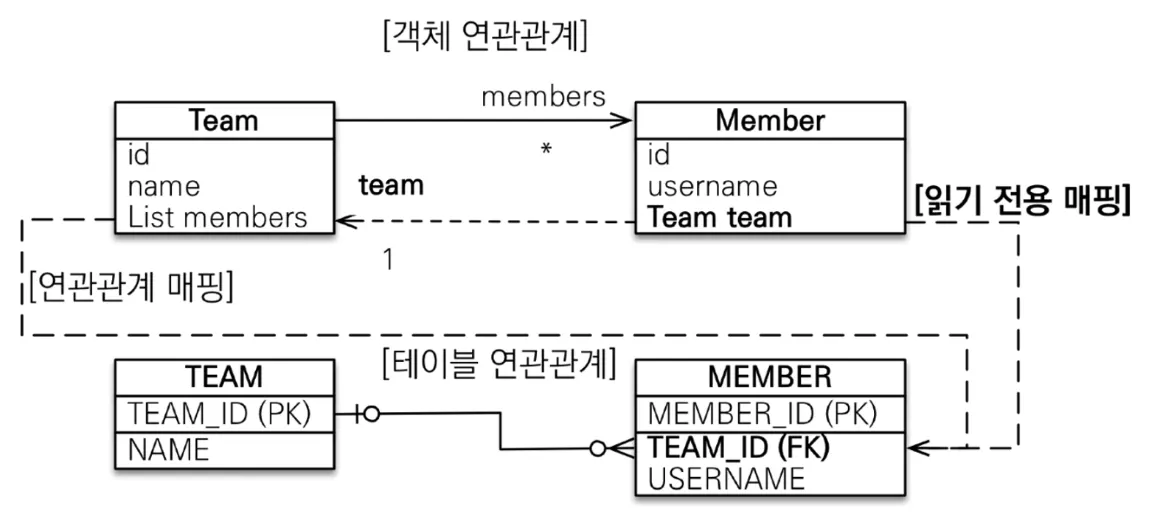
@ManyToOne
@JoinColumn(name = "TEAM_ID", insertable=false, updatable=false) // 본인 컬럼
private Team team;
Java
복사
•
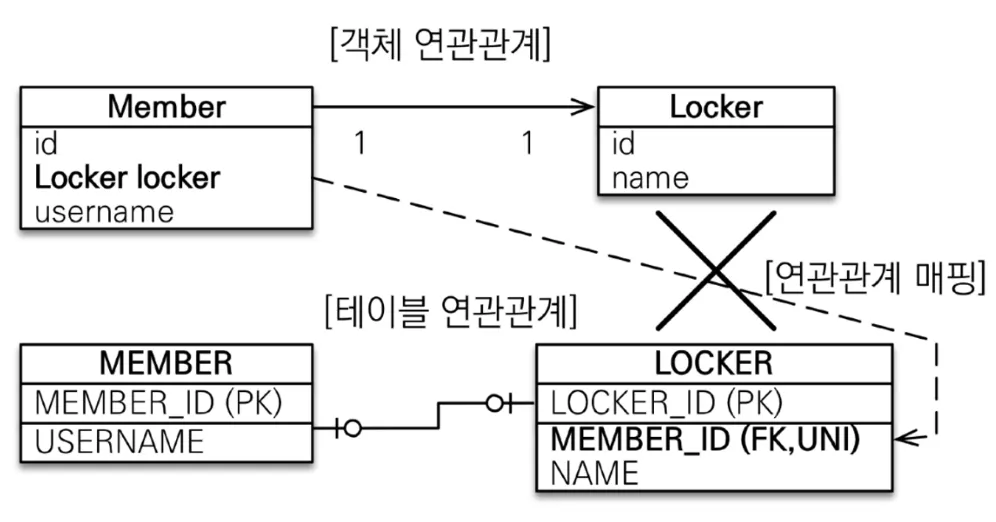
일대일(1:1)(@OneToOne)
◦
일대일에서는 FK가 어느 쪽이든 존재할 수 있기 때문에 FK를 본인이 가지고 관리하는 단방향과 다른 테이블의 FK를 관리하는 단방향 두 가지를 생각해볼 수 있는데, 후자는 JPA가 지원하지 않음(무쓸모)
◦
FK가 본인에게 있는 단방향(Member 엔티티가 FK를 소유하고 관리하는 경우)
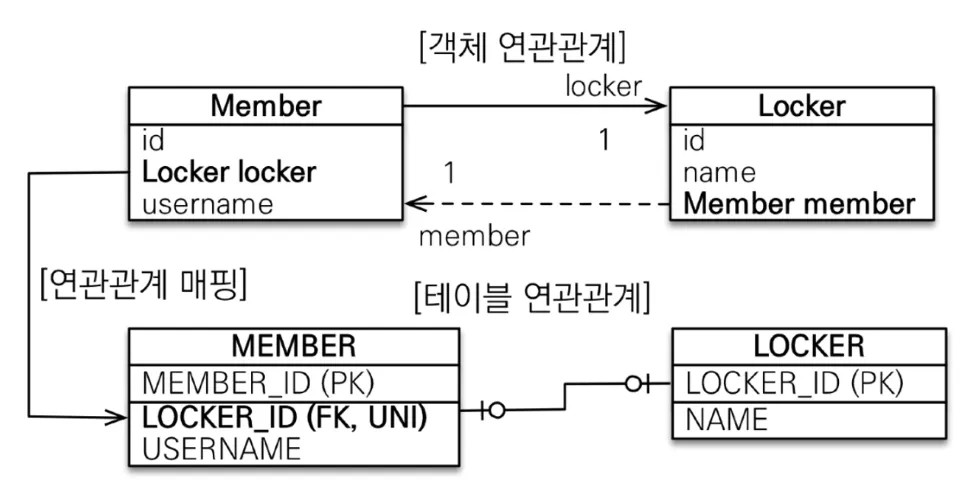
@OneToOne
@JoinColumn(name = "LOCKER_ID")
private Locker locker;
Java
복사
◦
FK가 다른 테이블에 있는 단방향 - 지원하지 않음
◦
양방향 - 읽기 전용(Locker 엔티티가 FK를 소유하고 관리하는 경우)
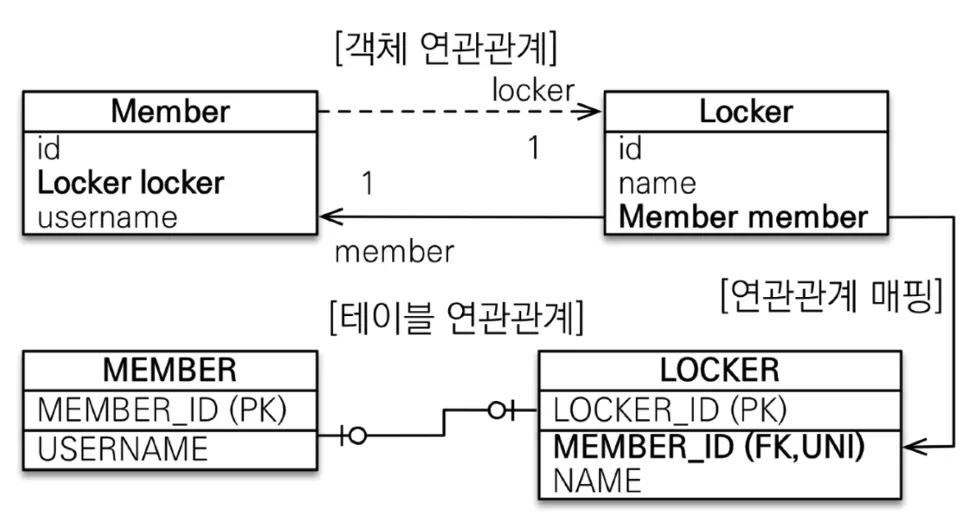
@OneToOne(mappedBy = "member")
private Locker locker;
Java
복사
◦
어느 쪽이 FK를 가지게 할 것이냐는 장단점이 있는데, 보통 Member쪽에 많이 둠
•
다대다(M:N)(@ManyToMany) - 관계형DB는 다대다 관계 표현이 불가능해서 중간에 연결 테이블을 추가해서 일대다, 다대일 관계로 풀어냄
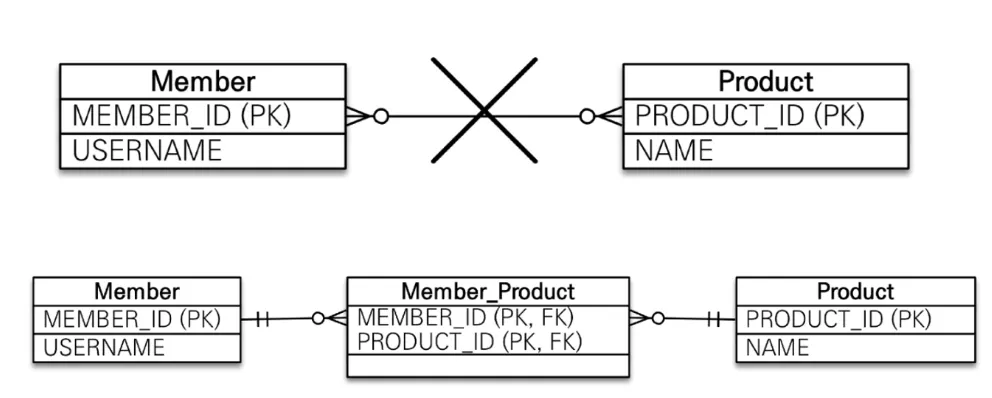
◦
반면 객체는 컬렉션을 이용해서 객체 2개로 다대다 관계 가능
◦
편리해보이지만 실무에서 사용 금지. 연결 테이블을 엔티티로 승격해서 @OneToMany와 @ManyToOne으로 해결
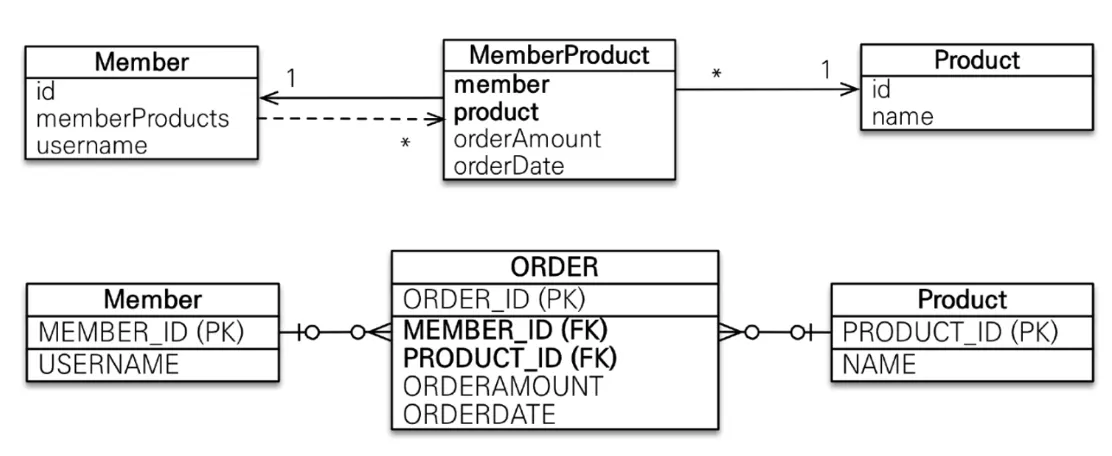
◦
연결 테이블에도 ID를 두는 것을 추천
상속관계 매핑
•
@Inheritance(strategy=InheritanceType.XXX) - 엔티티 클래스 레벨에 부착
◦
SINGLE_TABLE 전략 - 하나의 테이블에 몰빵 - Default
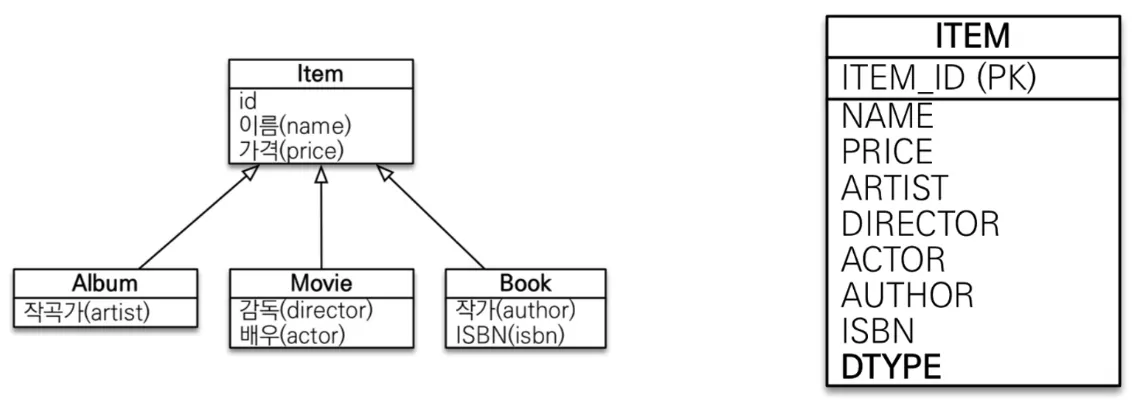
▪
테이블이 커지기 때문에 조인이 필요 없어 조회 성능이 빠름
▪
자식 엔티티가 매핑한 컬럼은 모두 null을 허용하는 단점
▪
단순한 경우 추천
◦
JOIND 전략 - 부모, 자식 테이블을 각각 생성
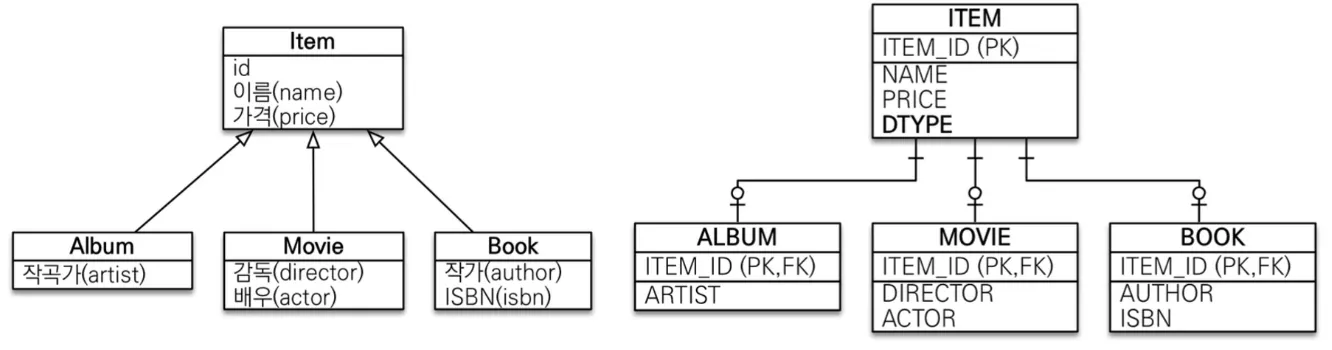
▪
정교한 설계 가능
◦
TABLE_PER_CLASS 전략 - 부모 테이블이 생기지 않음
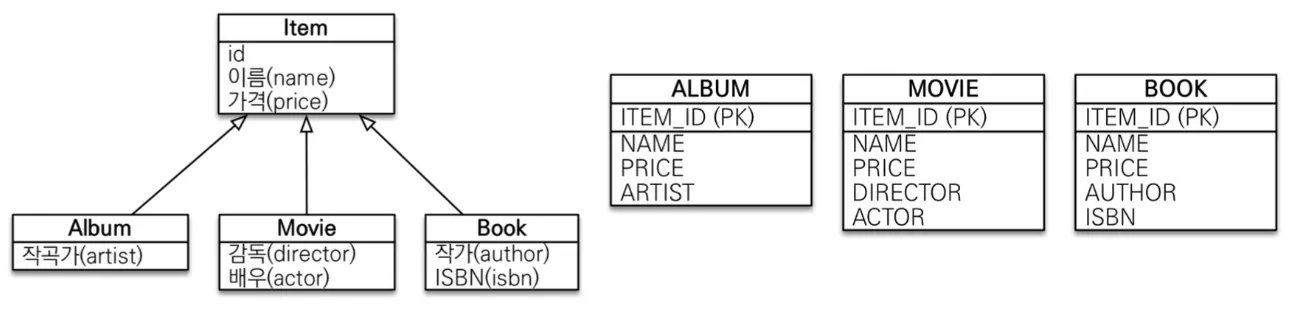
▪
비추천
•
@DiscriminatorColumn
◦
DTYPE이라는 컬럼을 만들어 자식 테이블 이름 기록
◦
자식 테이블 이름은 자식 엔티티 필드에 @DiscriminatorValue("M") 처럼 바꿀 수 있음
•
상속은 복잡도를 크게 올리기 때문에 신중해야 함
MappedSuperclass
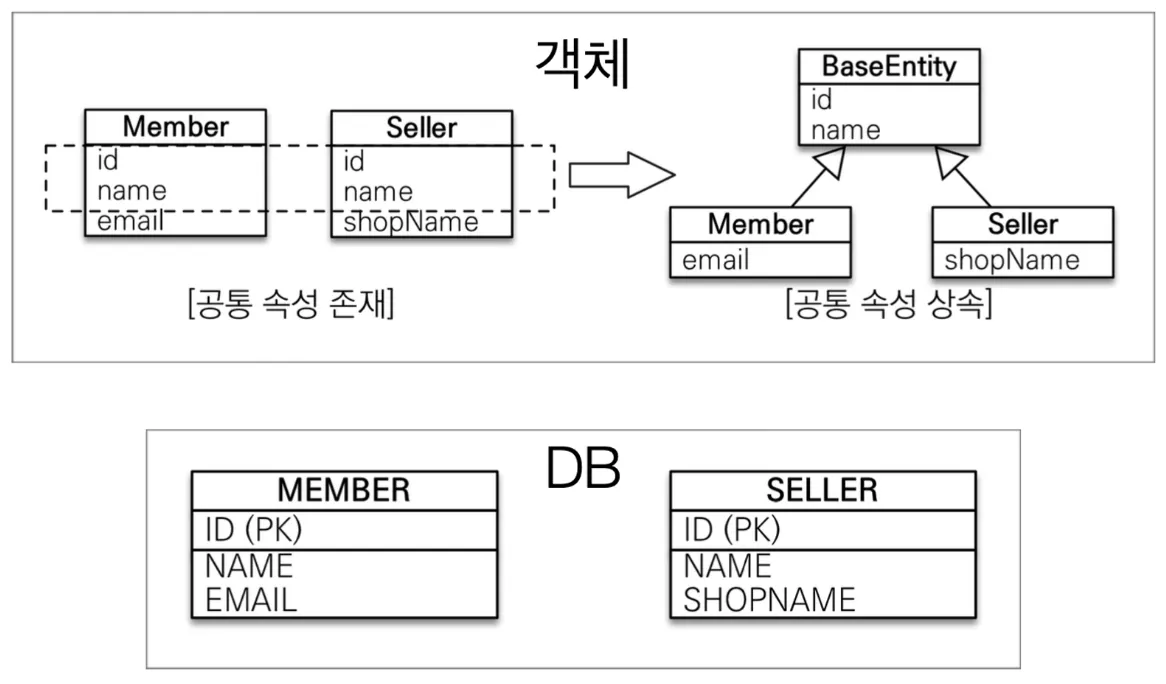
•
단순히 다른 엔티티 속성을 끌어다 쓰고 싶을 때 사용. 상속관계는 아님
◦
엔티티는 엔티티 아니면 MappedSuperclass만 상속 가능
•
엔티티가 아니라 직접 생성해서 사용할 일 없으므로 추상 클래스 권장
프록시(proxy)
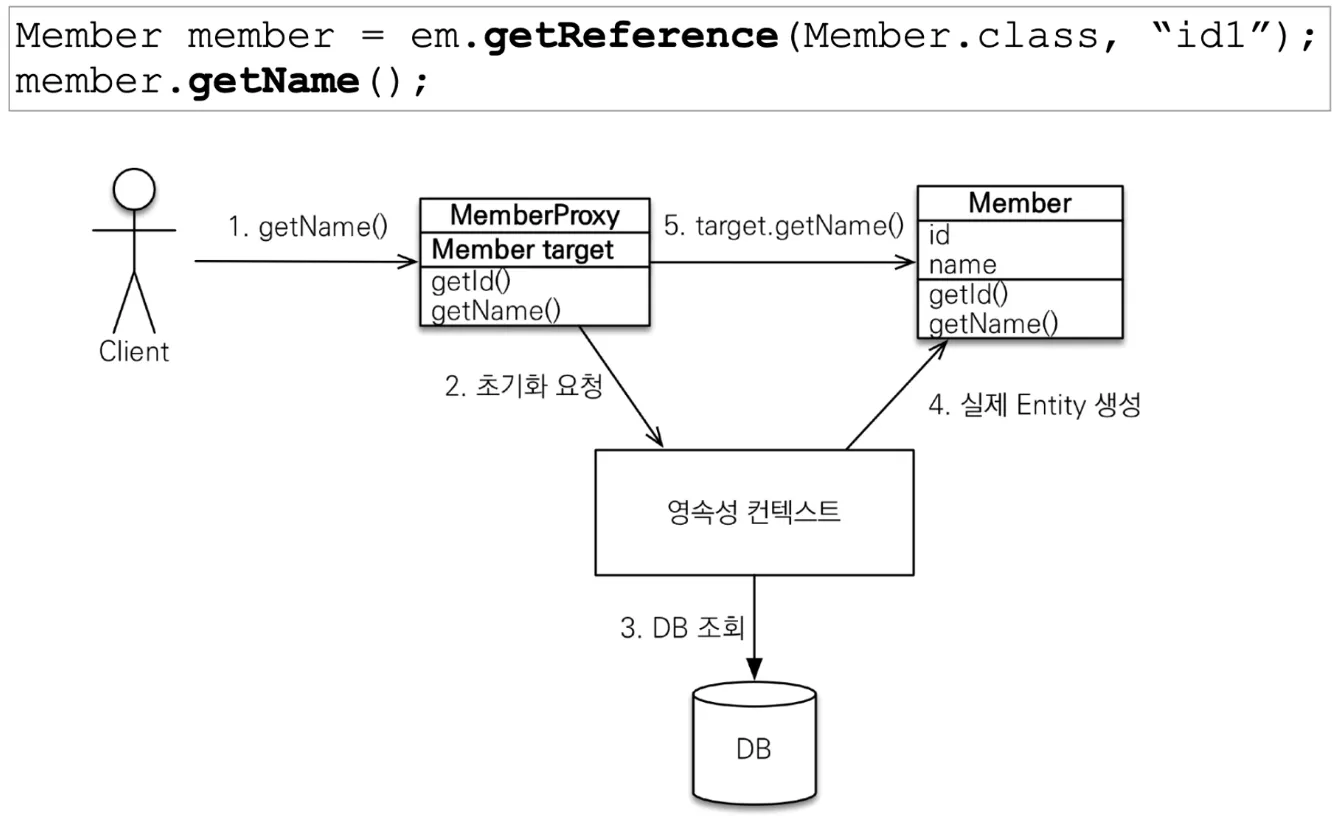
•
하이버네이트가 지연로딩을 구현하는 기술
•
실제 클래스를 상속받아서 만들어진 가짜 객체로, 겉모양이 같음
•
프록시에는 실제 객체의 id만 들고 있고, 필드나 메서드는 비어있어서 실제 객체의 필드나 메서드를 호출하도록 위임되어 있음
•
프록시의 필드나 메서드를 최초로 호출하면 프록시가 영속성 컨텍스트에 초기화를 요청해서 실제 객체를 받아옴
◦
Id는 프록시가 알고 있기 때문에 id를 조회할 때는 초기화되지 않음
◦
당연하게도 영속성 컨텍스트에 이미 객체가 있는 경우 굳이 프록시가 아니라 실제 엔티티를 찾아줌
•
준영속 상태에서 프록시를 초기화하면 문제가 발생(하이버네이트는 LazyInitializationException 예외)
지연 로딩(Lazy Loading)
•
연관관계 매핑에서 아래처럼 엔티티 조회 시 참조하는 다른 엔티티의 프록시만 들고 있는 지연로딩, 실제 객체를 DB에서 모두 가져오는 즉시로딩 선택 가능
@ManyToOne(fetch = FetchType.LAZY) // 지연로딩, 즉시로딩은 EAGER
@JOinColumn(name = "TEAM_ID")
private Team team;
Java
복사
•
하지만 가급적 모든 경우에서 지연로딩 사용하고 필요한 경우만 JPQL fetch join이나 batchsize, 엔티티 그래프 기능을 이용
◦
즉시 로딩은 N+1 문제를 일으킴
▪
N+1 문제란 조회 시 1개의 쿼리를 생각하고 설계를 했으나 나가지 않아도 되는 조회의 쿼리가 N개가 더 발생하 것을 말함

◦
@ManyToOne, @OneToOne은 기본이 즉시로딩이기 때문에 위처럼 LAZY로 설정
영속성 전이와 고아 객체
•
영속성 전이(CASCADE)
◦
특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만드는 것
◦
자식을 관리하는 부모가 하나이고, 부모와 자식의 라이프 사이클이 똑같을 때 사용하는 의미가 있음
•
영속성 전이 사용법
◦
종류(ALL, PERSIST 정도만 사용됨)
옵션 | 종류 |
ALL | 모두 적용 |
PERSIST | 영속 - 안전하게 저장만 할 때 |
REMOVE | 삭제 |
MERGE | 병합 |
REFREST | REFRESH |
DETACH | DETACH |
◦
단수쪽 엔티티에 설정할 경우
@OneToMany(mappedBy = "team", cascade = CascadeType.PERSIST)
private List<Member> members = new ArrayList<>();
Java
복사
▪
cascade 속성이 없어도 연관관계를 맺는 데는 아무 영향이 없음. 즉, 연관관계와 무관함
▪
위 전이를 이용하려면, 아래처럼 연관관계도 정상적으로 맺어주고, 영속성 전이를 위해 컬렉션에도 넣어줘야 함.
member1.setTeam(teamA); // 연관관계 매핑 - 필수
teamA.getMembers().add(member1); // 영속성 전이를 위해 컬렉션에 추가
em.persist(teamA); // member1은 자동 persist
Java
복사
▪
연관관계 매핑을 생략하면 member1은 DB에 영속성 전이로 등록은 되지만 TEAM_ID FK가 null로 들어감. 즉, 영속선 전이와 연관관계(FK) 매핑은 아무 관련이 없음
◦
다수쪽 엔티티에 설정할 경우
@ManyToOne(fetch = FetchType.LAZY, cascade = CascadeType.PERSIST)
@JoinColumn(name = "TEAM_ID_FK")
private Team team;
Java
복사
member1.setTeam(teamA); // 연관관계 매핑 - 필수
em.persist(member1); // teamA는 자동 persist
Java
복사
•
고아 객체
◦
부모 엔티티와 연관관계가 끊어진 자식 엔티티를 자동으로 삭제하는 기능
@OneToMany(mappedBy = "parent", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Child> children = new ArrayList<>();
Java
복사
teamA.getMembers().remove(0);
Java
복사
이렇게 할 경우 컬렉션에서 삭제된 멤버에 대해 DELETE문이 쿼리로 나감
◦
cascade=CascadeType.REMOVE와 orphanRemoval=true의 공통점
▪
부모를 em.remove(parent)할 경우
•
부모에 cascade=CascadeType.REMOVE만 있는 경우에도
◦
부모를 삭제하기 때문에 자식들도 자동으로 삭제 됨
•
부모에 orphanRemoval=true만 있을 경우에도
◦
부모가 삭제되어 연관관계가 모두 끊어지기 때문에 자식들도 자동으로 삭제 됨
▪
cascade=CascadeType.ALL과 orphanRemoval=true를 같이 쓰면 부모와 자식이 생명주기를 같이 하게 됨
값타입
•
JPA의 데이터 타입 분류
◦
엔티티 타입
◦
값 타입
▪
기본값 타입(int, String, Integer, …)
▪
임베디드 타입(embedded type, 복합 값 타입)
▪
컬렉션 값 타입
•
임베디드 타입
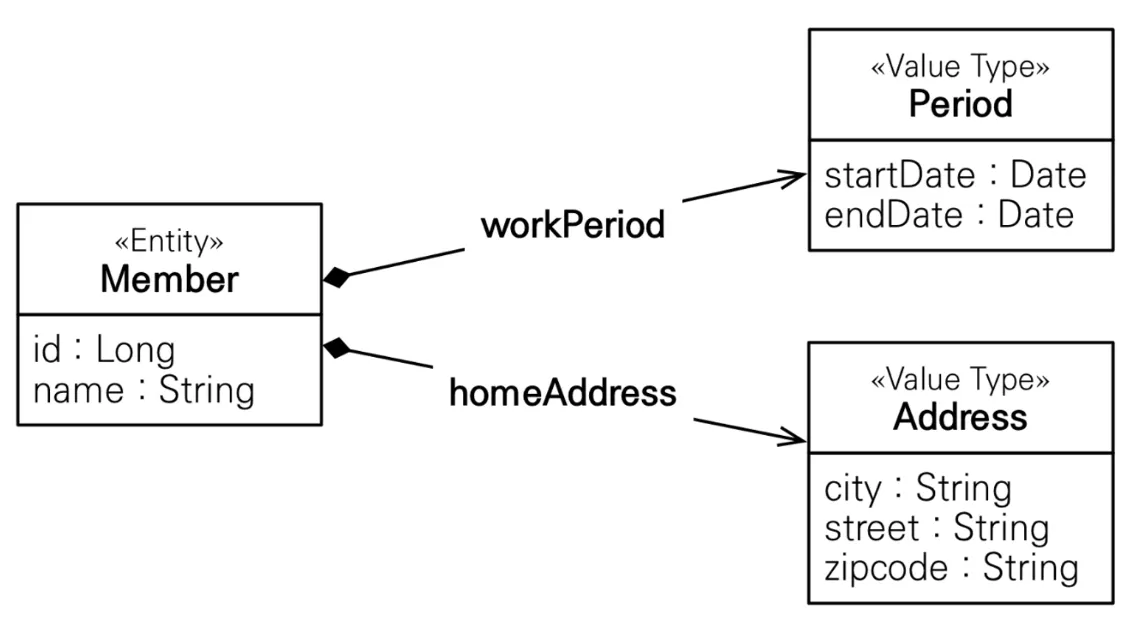
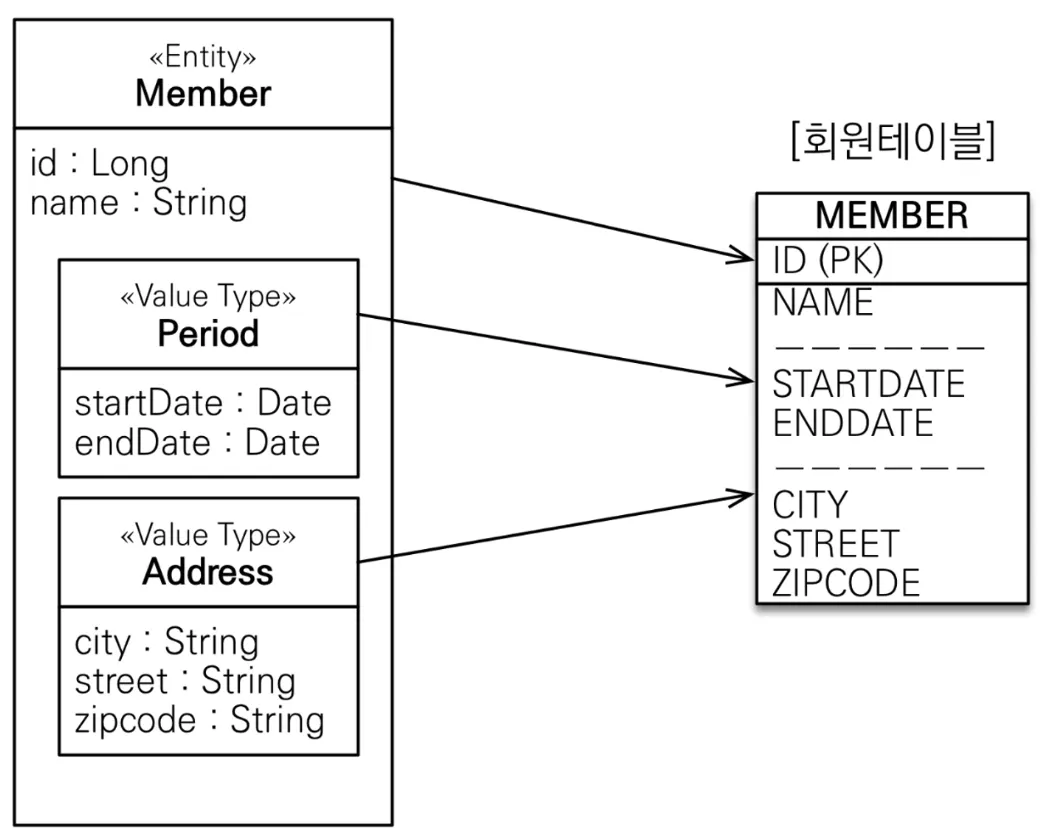
◦
다른 값 타입(주로 기본 값 타입)을 모아서 만든 값 타입
◦
사용법 - 아래 둘 중 하나 사용하면 됨. 하지만 둘 다 붙일 것을 권장
▪
임베디드 타입 클래스에 @Embeddable
▪
엔티티의 임베디드 타입 참조 필드에 @Embedded
임베디드 값타입은 엔티티를 참조로 들고있을 수 있음. 단, 여러 엔티티에서 사용할 수 있기 때문에 읽기 전용으로 설정해야 함(예시 보려면 펼치기)
@AttributeOverrides, @AttributeOverride로 컬럼 이름 오버라이드 가능(예시 보려면 펼치기)
◦
임베디드 값타입은 setter를 없애 불변 객체(immutable obejct)로 만들어야 부작용을 막을 수 있음
◦
equals()와 hashCode()를 적절히 오버라이드 할 것(보통 모든 필드를 활용해서 IDE 자동 생성 사용)
•
값 타입 컬렉션
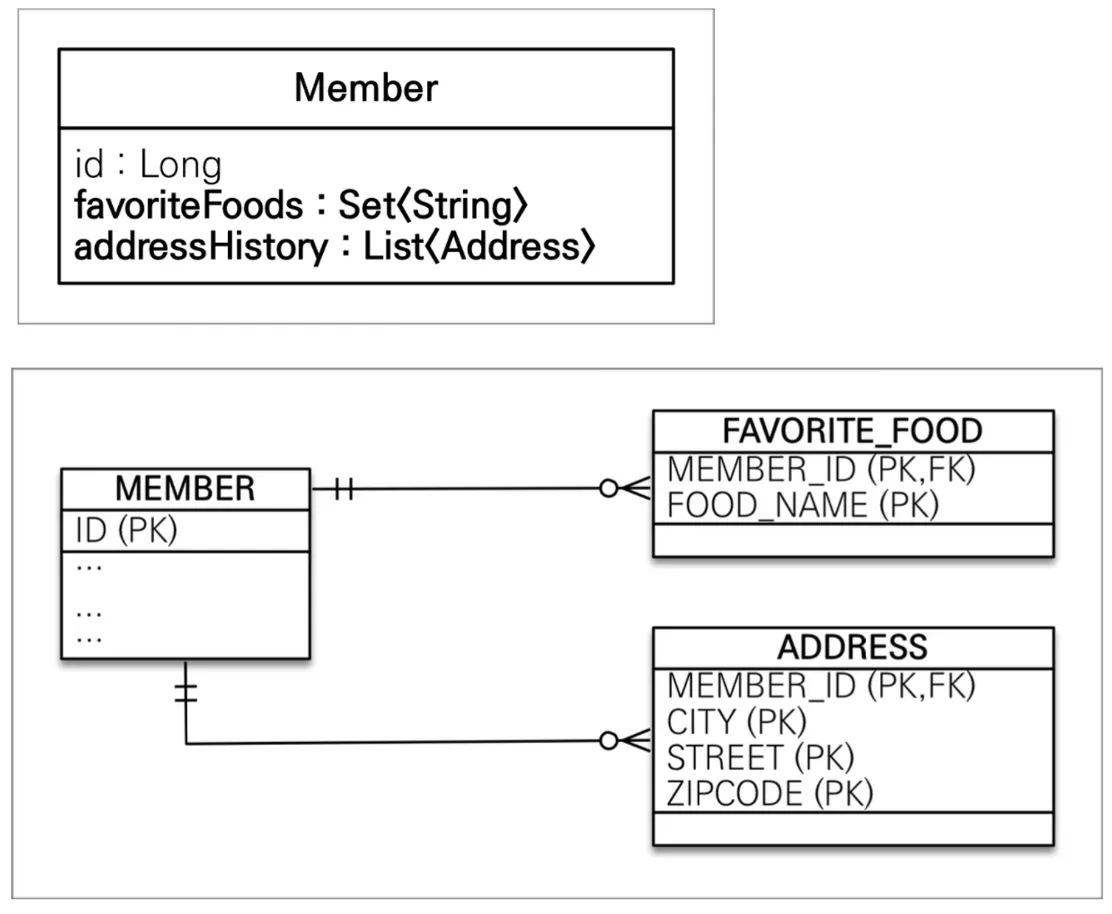
◦
값 타입을 하나 이상 저장할 때 사용
◦
사용법
@ElementCollection과 @CollectionTable 병기(예시 보려면 펼치기)
◦
영속성 전이(cascade)와 orphanRemoval 기능을 필수로 가짐
◦
기본 지연 로딩
◦
식별자 개념이 없어서 변경 시 추적이 어렵고 컬렉션 변경 시 부모 엔티티와 관련된 모든 데이터가 삭제된 후 다시 저장됨
◦
식별자가 필요하고, 지속해서 값을 추적, 변경해야 한다면 값 타입 컬렉션을 엔티티로 승격시킨 후 영속성 전이와 orphanRemoval 기능을 사용해 값 타입 컬렉션처럼 사용해야 함
JPQL(Java Persistence Query Language)
•
JPA가 지원하는 여러 쿼리 방법 중 하나
◦
JPQL
▪
객체를 대상으로 쿼리하는 언어로, JPA가 SQL로 바꿔서 DB로 보내줌
▪
SQL과 매우 유사
◦
QueryDSL - 자바 코드로 JPQL 작성. 동적 쿼리 작성에 편리. 실무 사용 권장
◦
네이티브 SQL - SQL을 직접 사용하는 기능
◦
JDBC 직접 or JdbcTemplate/MyBatis와 함께 사용
◦
Criteria - 복잡해서 망함
•
기본 사용 예시
TypedQuery<Member> query1 = em.createQuery("select m from Member m", Member.class);
TypedQuery<String> query2 = em.createQuery("select m.username from Member m", String.class);
Query query3 = em.createQuery("select m.username, m.age from Member m");
TypedQuery<Member> query4 = em.createQuery("select m from Member m where m.username = 'kim'", Member.class);
List<Member> resultList1 = query1.getResultList();
List<String> resultList2 = query2.getResultList();
List resultList3 = query3.getResultList();
Member singleResult = query4.getSingleResult();
//파라미터 바인딩
Member foundMember = em.createQuery("select m from Member m where m.username = :username", Member.class)
.setParameter("username", "kimnaparklee")
.getSingleResult();
System.out.println("foundMember.getUsername() = " + foundMember.getUsername());
Java
복사
•
페이징
em.createQuery()
.setFirstResult(0) // 첫번째 결과부터
.setMaxResults(3) // 3개 가져오기
.getResultList();
Java
복사
•
서브 쿼리
◦
하이버네이트 6 이전 - SELECT, WHERE, HAVING 절에서 사용 가능
◦
하이버네이트 6 부터 - FROM절의 서브쿼리 지원
•
경로 표현식
◦
점(.)을 찍어 객체 그래프 탐색 가능
◦
묵시적 내부 조인이 발생하기 때문에 명시적 JOIN을 해서 혼란을 없애는 것을 추천
•
페치 조인(객체 그래프)
◦
모든 지연 로딩 설정을 오버라이딩하면서 즉시 로딩을 해오는 기능
◦
지연 로딩 시 생길 수 있는 N+1 문제를 방지
◦
컬렉션 패치 조인
▪
하이버네이트 6 이전
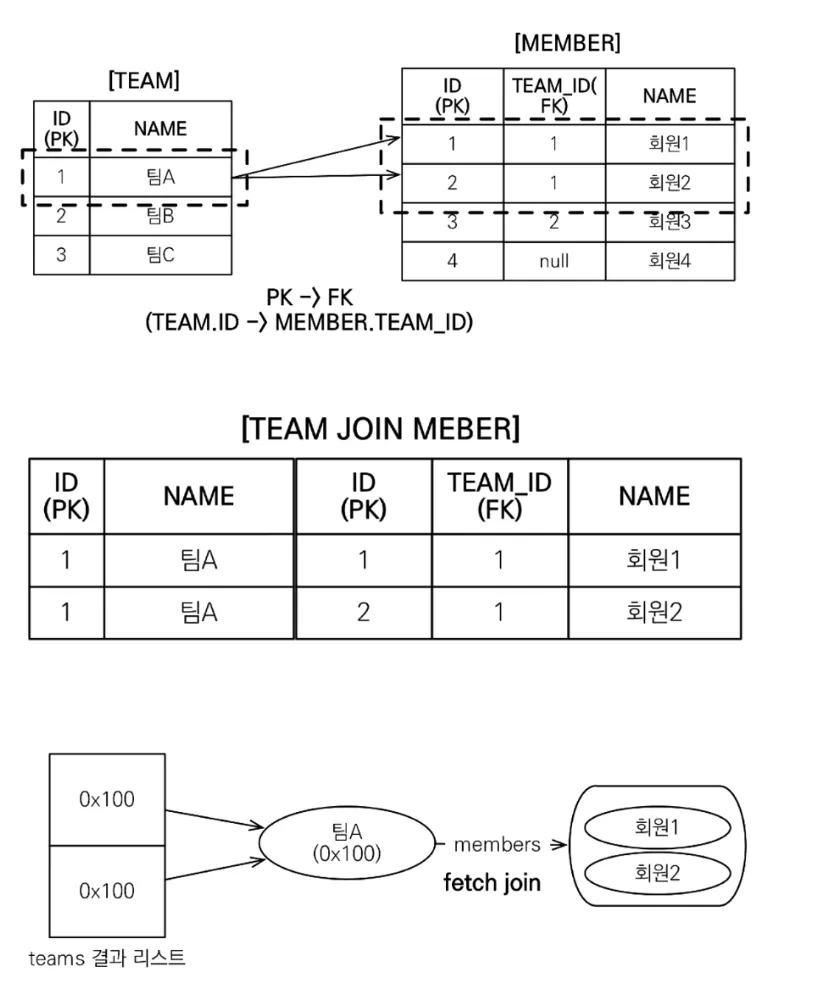
•
일대다이기 때문에 레코드가 뻥튀기 돼서 들어옴. 즉, 영속성 컨텍스트는 하나의 객체가 들어오지만 반환되는 resultList에는 이 하나의 객체가 다수쪽에 매핑된 개수만큼 중복돼서 들어가 있음
•
DISTINCT를 추가하면
SQL에 DISTINCT가 추가되고(물론 다수쪽 데이터가 모두 다르므로 중복 제거에 실패함)
◦
애플리케이션 수준에서 또 resultList상 엔티티 중복을 제거해줌
▪
하이버네이트 6 부터 DISTINT 명령어를 사용하지 않아도 애플리케이션 수준에서 자동 중복 제거
◦
페치 조인의 한계
▪
컬렉션 패치 조인을 사용하면 레코드 뻥튀기 때문에 페이징 API 사용 불가(일대일, 다대일은 가능)
•
만약 페이징을 한다면 테이블의 모든 데이터를 메모리로 올려서 애플리케이션에서 작업해야 하는데, 매우 위험 천만한 행위. 레코드 100만개가 메모리로 올라온다고 생각해보자
▪
별칭 사용 불가 - where문 사용해서 가져올 시 고아 p 객체 제거 기능 등으로 인해 자식 객체가 삭제되는 등 정합성 이슈 발생 가능하기 때문
•
fetch 조인을 여러번 일어붙일 때 정도에 사용
▪
만약 엔티티가 가진 모양 그대로 데이터를 가져오는게 아닌 경우 일반 조인 + DTO 활용
•
벌크 연산
◦
dirty checking으로 여러 건을 수정하면 쿼리가 수정된 엔티티 개수만큼 나가게 됨
◦
이럴 경우 JPQL로 update 쿼리를 날려줘야 함. 결과값은 영향받은 레코드 수를 반환
◦
벌크 연산은 영속성 컨텍스트를 무시하고 DB에 직접 쿼리하는 것이기 때문에 벌크연산을 수행 후 영속성 컨텍스트를 자동 초기화(clear)함
▪
추후에 스프링 데이터 JPA에서 @Modifying의 clearAutomatically Attribute가 이 초기화 관련 설정임

